视频理解·续

主要内容
- 手工 -> CNN ✔️
- 双流网络 ✔️
- 3维卷积
- video transformer
抽取光流很慢,也很占空间。光流存储带来的IO很多。所以很多人想把这种方法换掉,使用3D CNN,希望能直接学视频。但实际上3D网络越做越大,结果也没解决性能问题。实际上光流还是好特征。
3D CNN
C3D
- Tran, Du, et al. “Learning spatiotemporal features with 3d convolutional networks.” Proceedings of the IEEE international conference on computer vision. 2015.
主要工作: 提出简单且有效的学习视频的时空特征的方法。
结果:
模型的结构:
总共有11层,卷积核均为
输入大小:
Conv2a:
Conv3a:
Conv4a:
Conv4a:
fc6:
可以从fc6抽特征给SVM,做分类,效果更快更好。fc6抽的特征叫C3D特征
结果:
效果挺好,比2D好
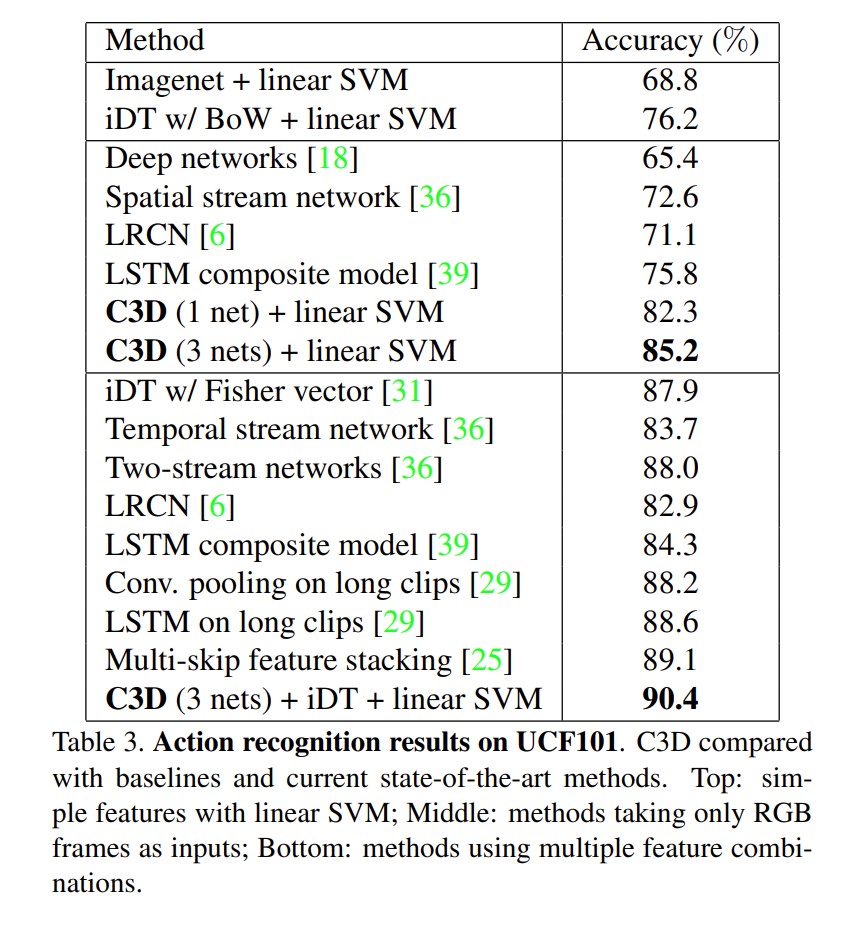
上面两个效果不好,不如之前的手工特征,也不如双流。整体上效果还是不好。文章的抽特征好,提供了python的实现,可以调接口。
I3D
- Carreira, Joao, and Andrew Zisserman. “Quo vadis, action recognition? a new model and the kinetics dataset.” proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.
模型:
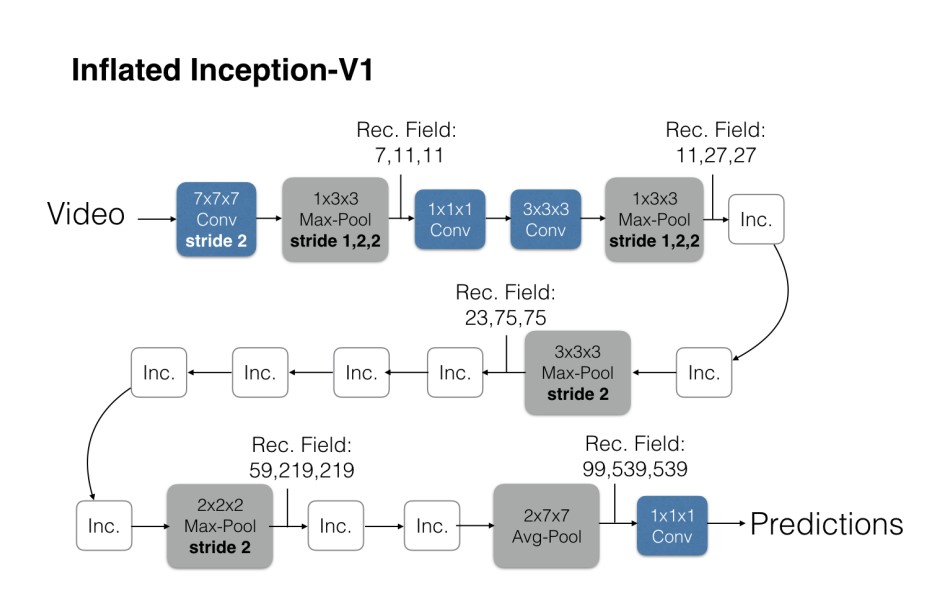
i即膨胀。预训练时使用2d数据,通过膨胀将2d转为3d的数据。i2d与i3d结构不变,卷积核变。不用再设计网络,只要扩充成3d,还能用之前用2d训练的模型参数
结果: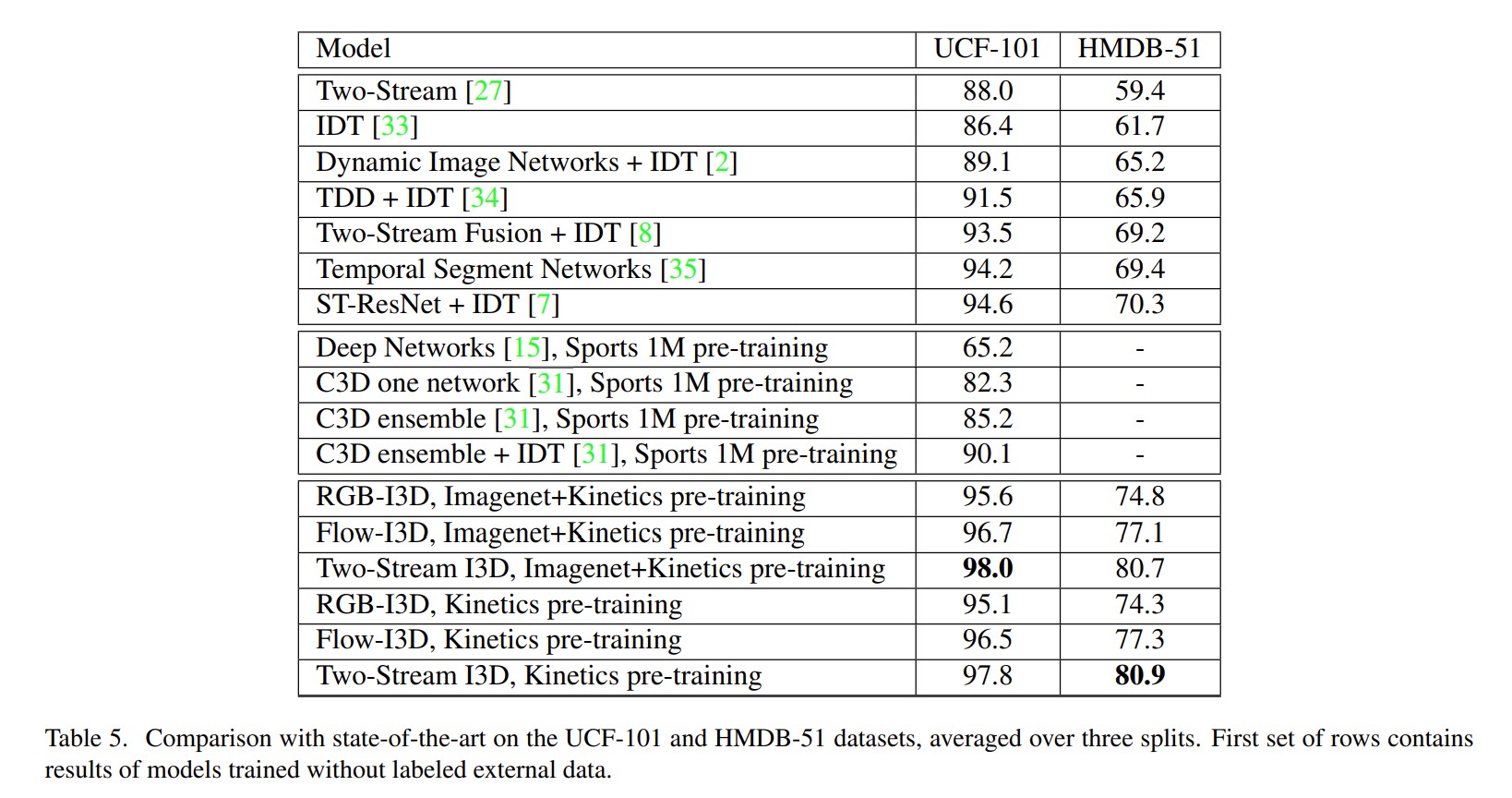
意义:
- 分别用了RGB和光流,效果很好
- 简单方法提供表现
- 证明2D网络迁移到3D网络的有效性
从此不用双流网络改用3D网络,数据集由UCF 101变成了K 400
ResNet -> ResNet3D
ResNext -> MFNet
SENet -> STCNet
Non-local
- Wang, Xiaolong, et al. “Non-local neural networks.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
3D网络大概已经定型,需要改进:时序上怎么建模?lstm可用,注意力很好
卷积和递归都是在局部上操作,作者提出non-local算子,是一个可以建模长距离信息的模块。
non-local block: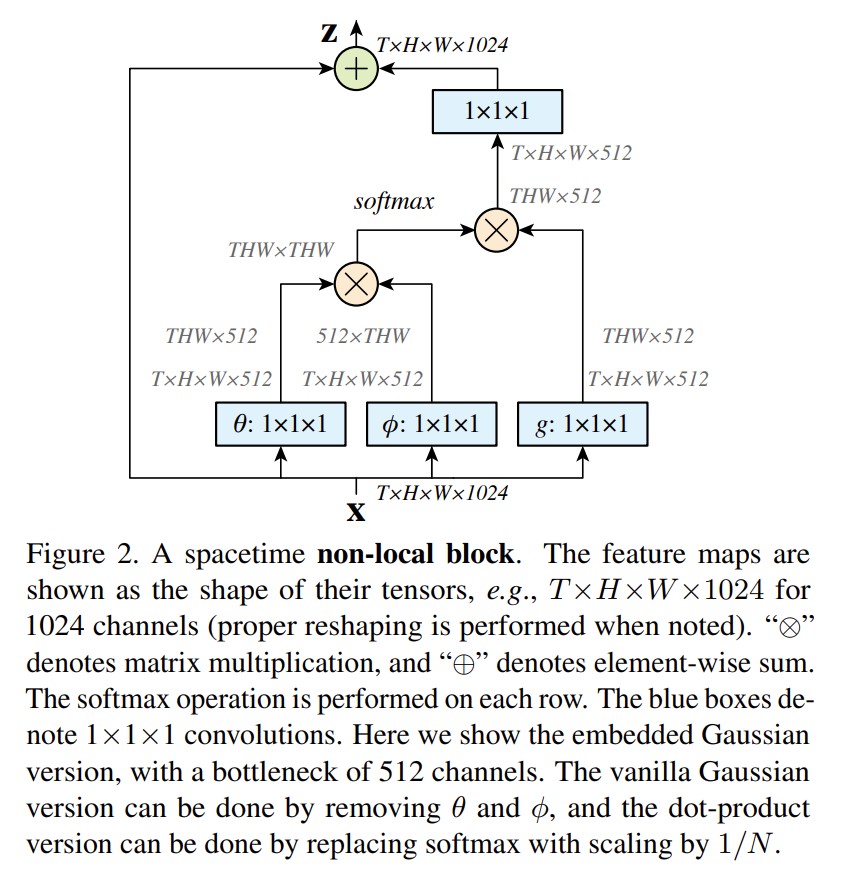
其实是自注意力操作。注意还有残差连接。注意力不多记录。
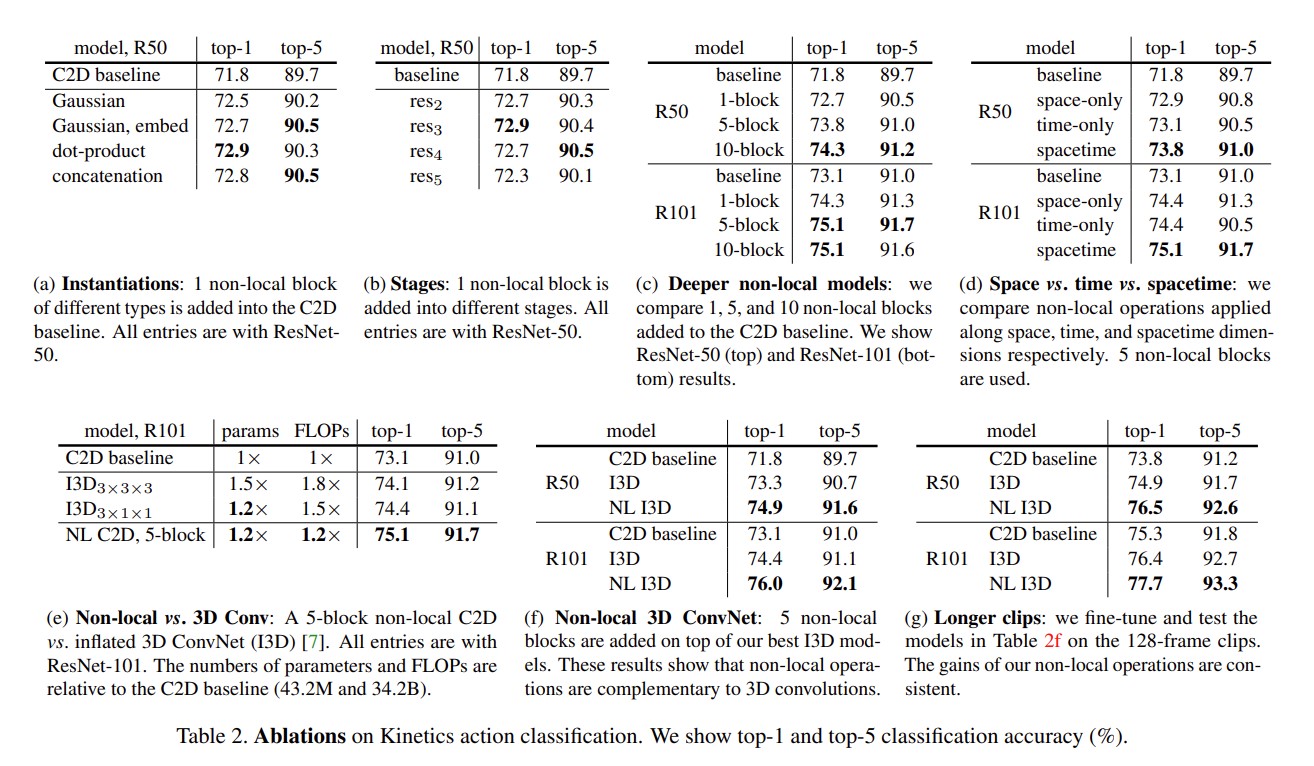
使用dot product做自注意力效果最好。
作者试了加在2或3号resnet后,发现在234上效果好,在5上不好。加上10个non-local block效果最好。时间空间上做自注意力都很重要。
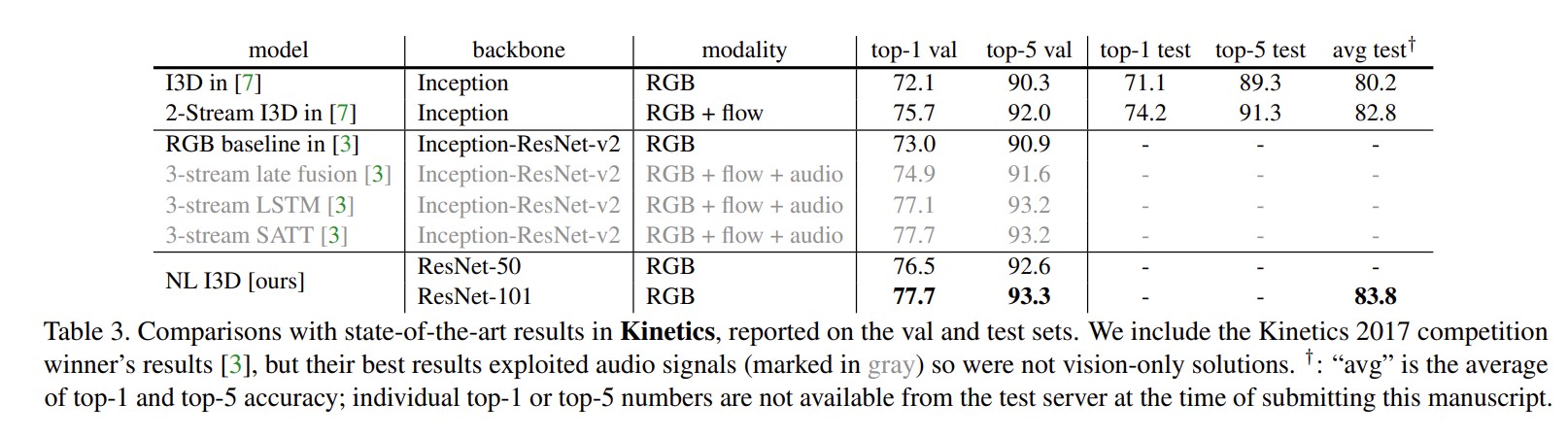
贡献
把注意力操作引入视频理解,把空间上的自注意力操作变成时间和空间上的自注意力操作。
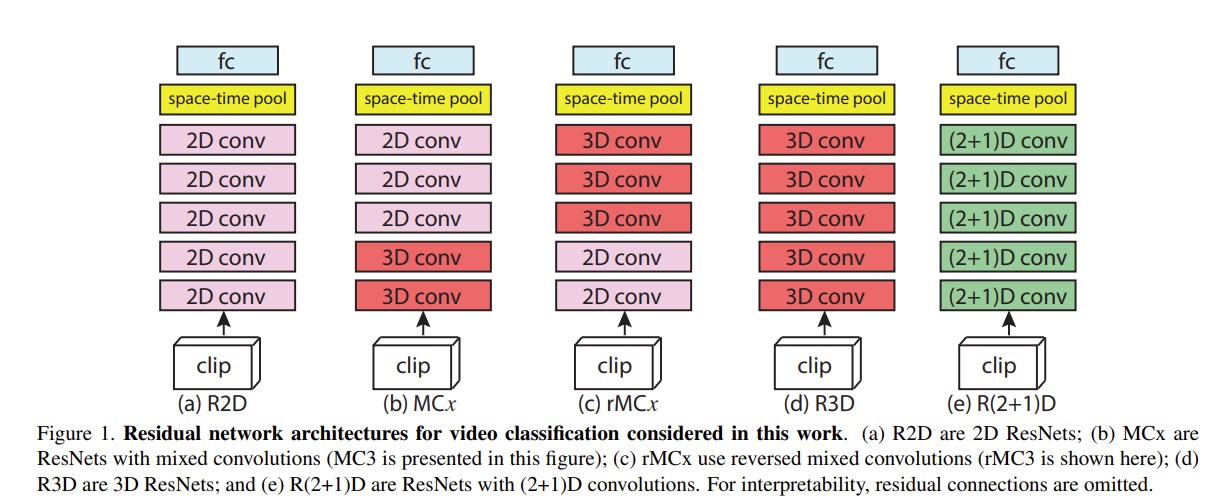
R(2+1)D
- Tran, Du, et al. “A closer look at spatiotemporal convolutions for action recognition.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018.
时空的卷积要怎么做?
把3D卷积拆成空间上的2D和时间上的1D效果更好。
实验
结果
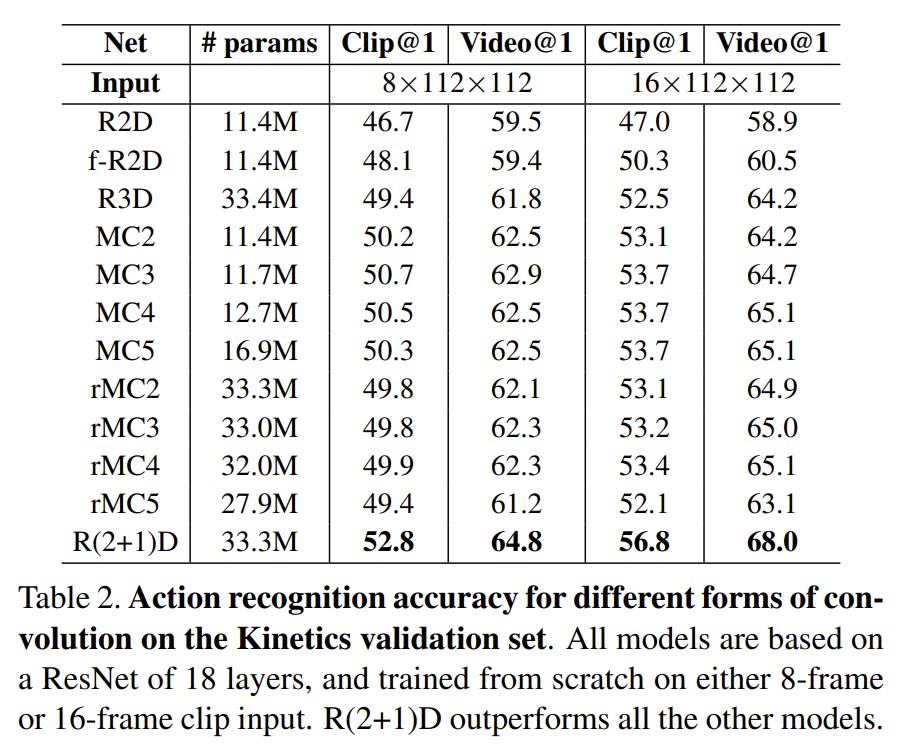
拆分
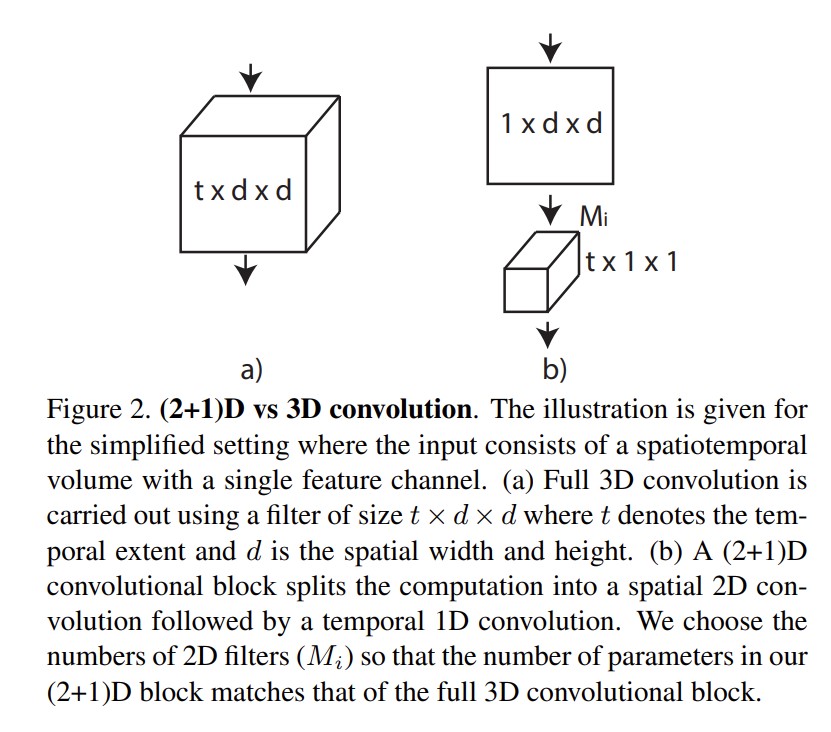
空间上
好处
模型的非线性强,学习能力更强一些,
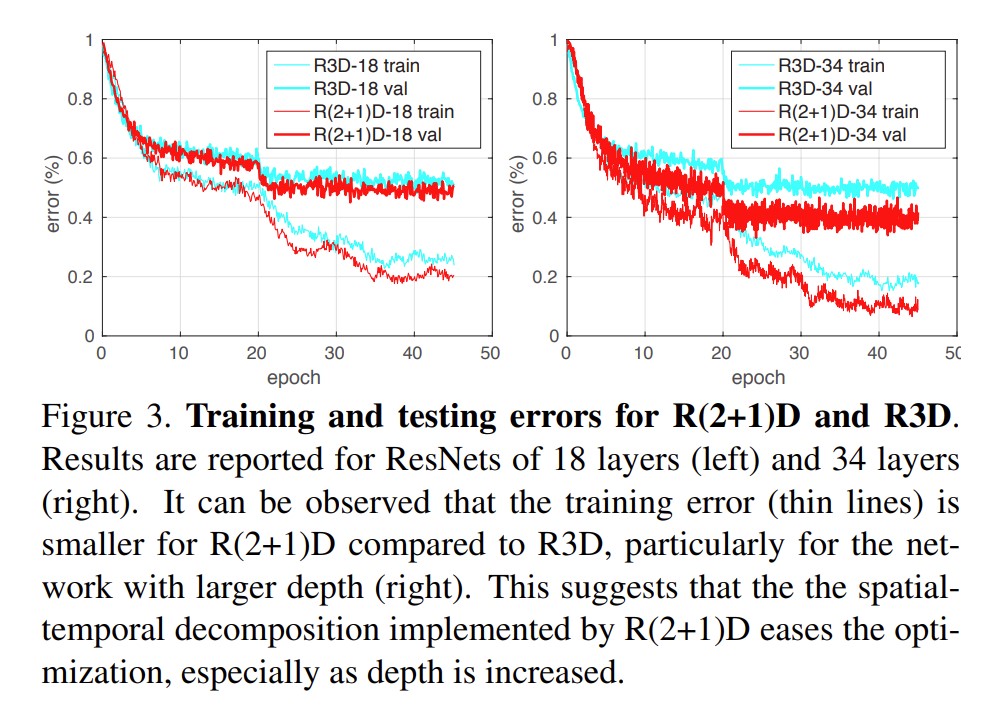
证明模型更容易训练
结果
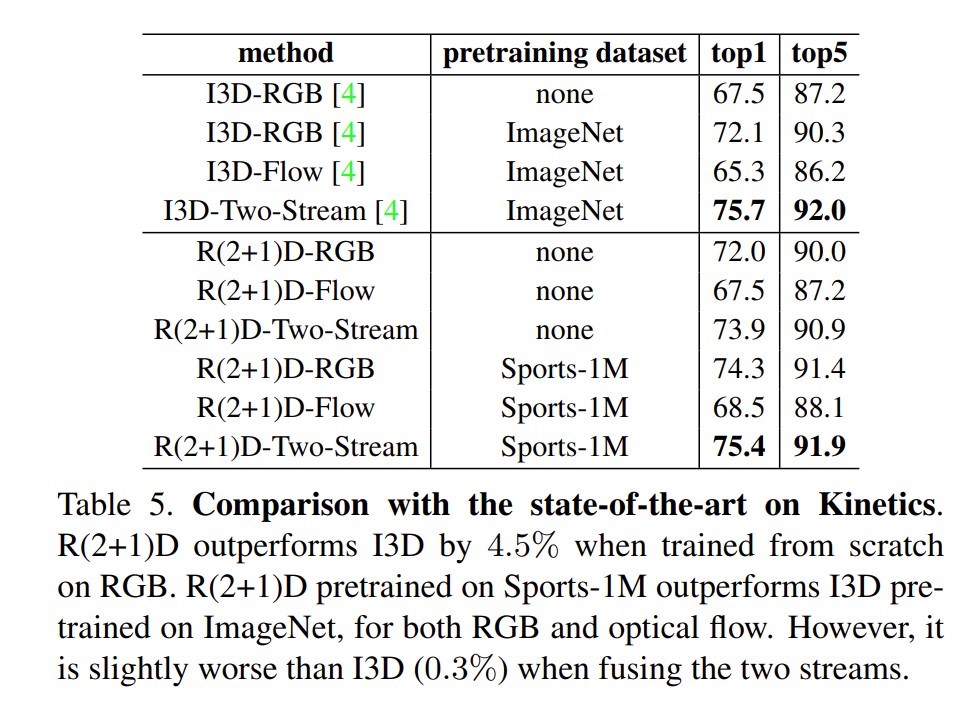
Slow Fast
- Feichtenhofer, Christoph, et al. “Slowfast networks for video recognition.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
单纯的3D网络,灵感来自人体视网膜的p细胞与m细胞,p细胞处理静止图像多,m细胞处理运动信息多。网络有一支是slow,一支是fast。在视频中以低采样率采样的是慢分支,在视频中稀疏地抽取帧,模型是I3D;快分支以高帧率采样,网络小一些。慢分支用小输入,大网络;快分支用大输入,小网络。分支之间用later connection结合起来,信息可以互相交互。达到速度与精度的结合。
模型
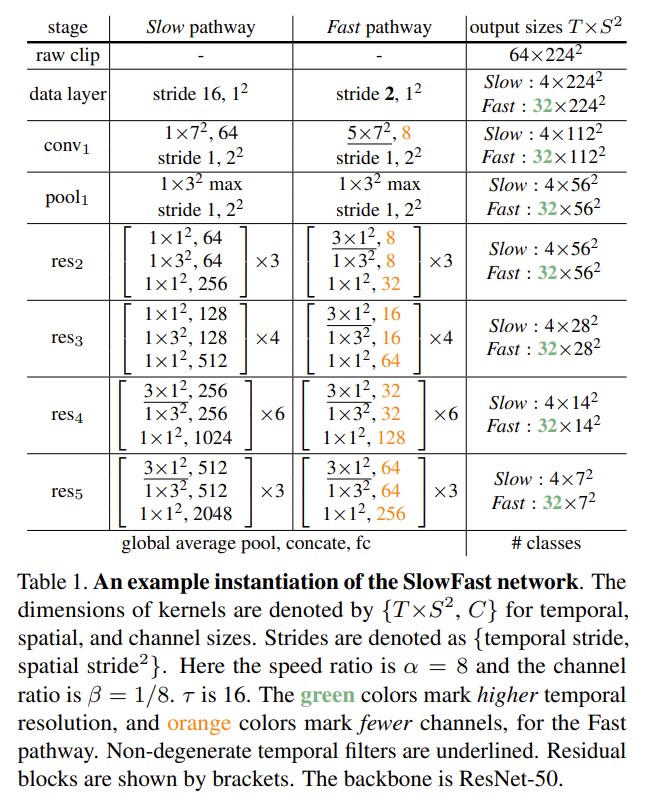
在时序上没进行下采样,希望保持这些帧,更好地学习这些信息。
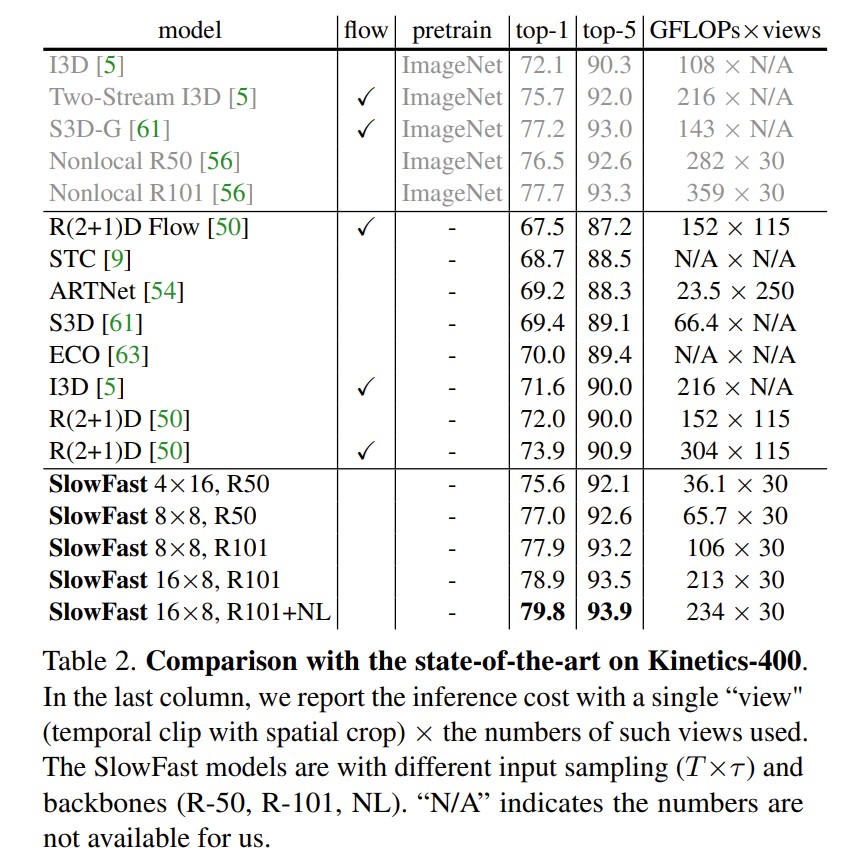
结果
Video transformer
Timesformer
- Bertasius, Gedas, Heng Wang, and Lorenzo Torresani. “Is space-time attention all you need for video understanding?.” ICML. Vol. 2. No. 3. 2021.
5种结构
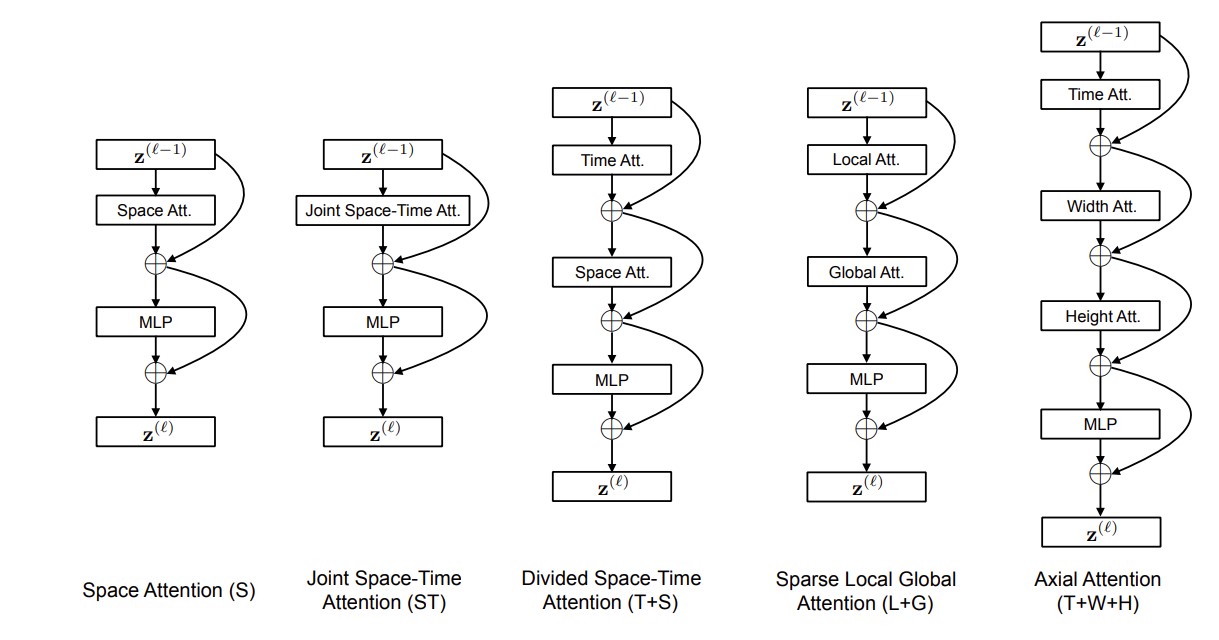
第2个是把三个维度一起做注意力,gpu内存装不下。3: 先在时间上注意力,然后在空间上注意力。4: 先在局部注意力,然后在全局算。5: 分别延3个轴做自注意力。
可视化

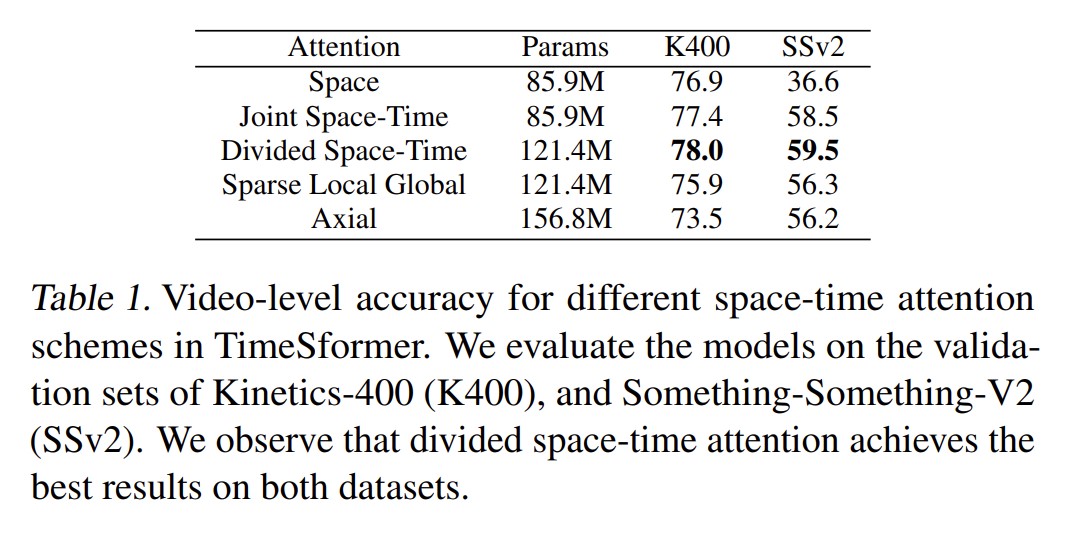
消融实验
显存的问题
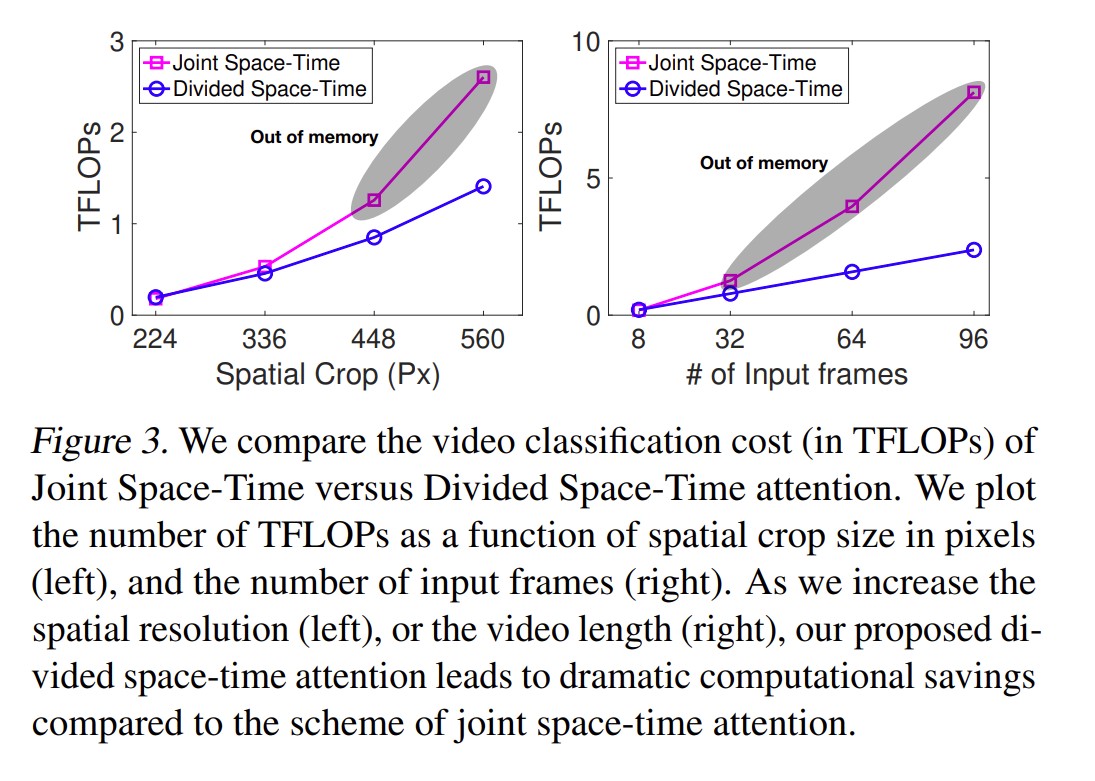
结果
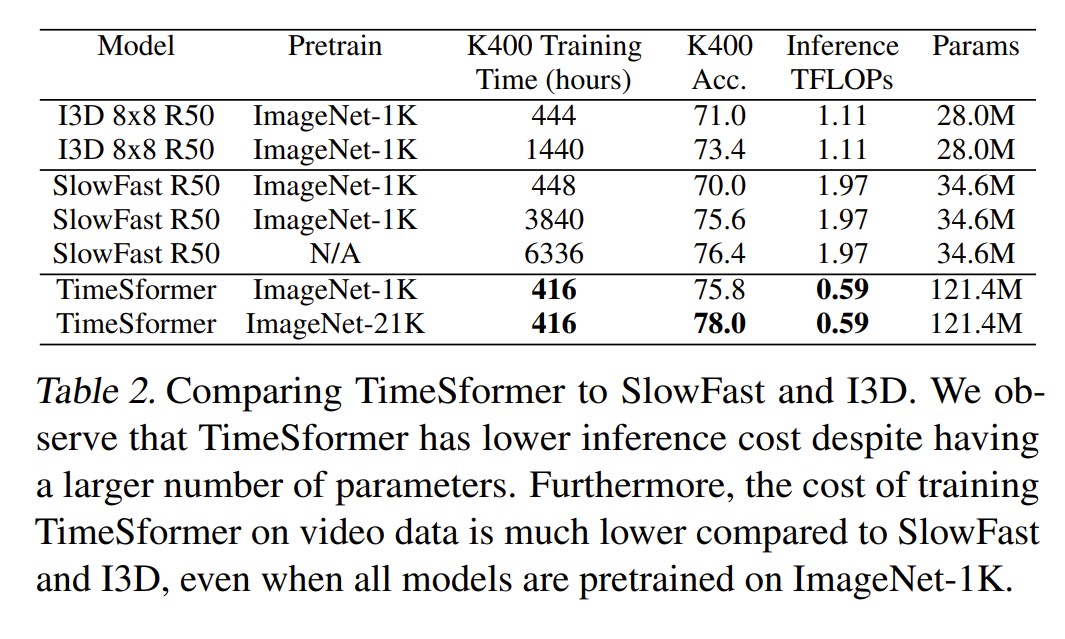
总结
简单效果好开销小,可以处理超过一分钟的视频。
总结
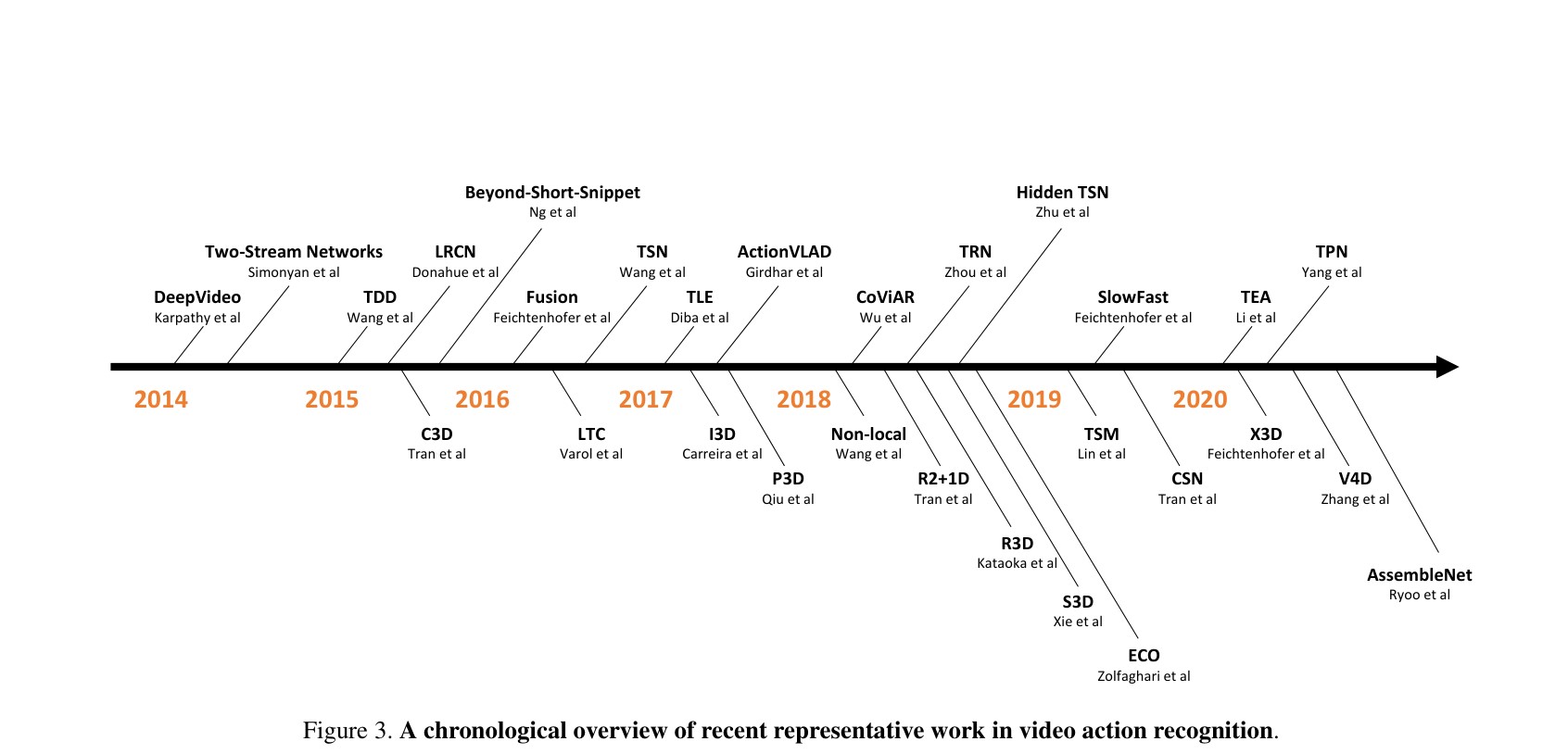
发展脉络:
- 标题: 视频理解·续
- 作者: MelodicTechno
- 创建于 : 2024-08-30 11:36:18
- 更新于 : 2026-02-17 18:51:17
- 链接: https://melodictechno.github.io./2024/08/30/video-understanding2/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。