
动作识别综述笔记

论文:Going deeper into action recognition: A survey
封面:神秘墨测兮
方法
描述动作的方法
Local representation based approaches
- Interest point detection
- Local descriptors
- Edge and motion descriptors
- Pixel pattern descriptors
- From cuboids to trajectories
- Aggregation
上述内容较基础且年代久远,暂不详细整理。
用于动作检测的深度学习网络架构
四种架构
- Spatiotemporal networks (时空网络)
- Multiple stream networks (多流网络)
- Deep generative networks (深度生成网络)
- Temporal coherency networks (时间相干网络)
以上中文翻译来自谷歌翻译,我认为中文名并不重要,不予深究。分类则应该是论文作者个人的观点。
Spatiotemporal networks
零碎的记录:
- pooling和weight-sharing用于减少网络搜索的空间;
- 三维卷积在卷积的基础上增加了时序信息,使用三维的卷积核。三维卷积神经网络输入的视频的帧数是预先确定的;
- 在将时序信息输入(fusion)卷积网络的方法中,最大池化表现很好(吴恩达);
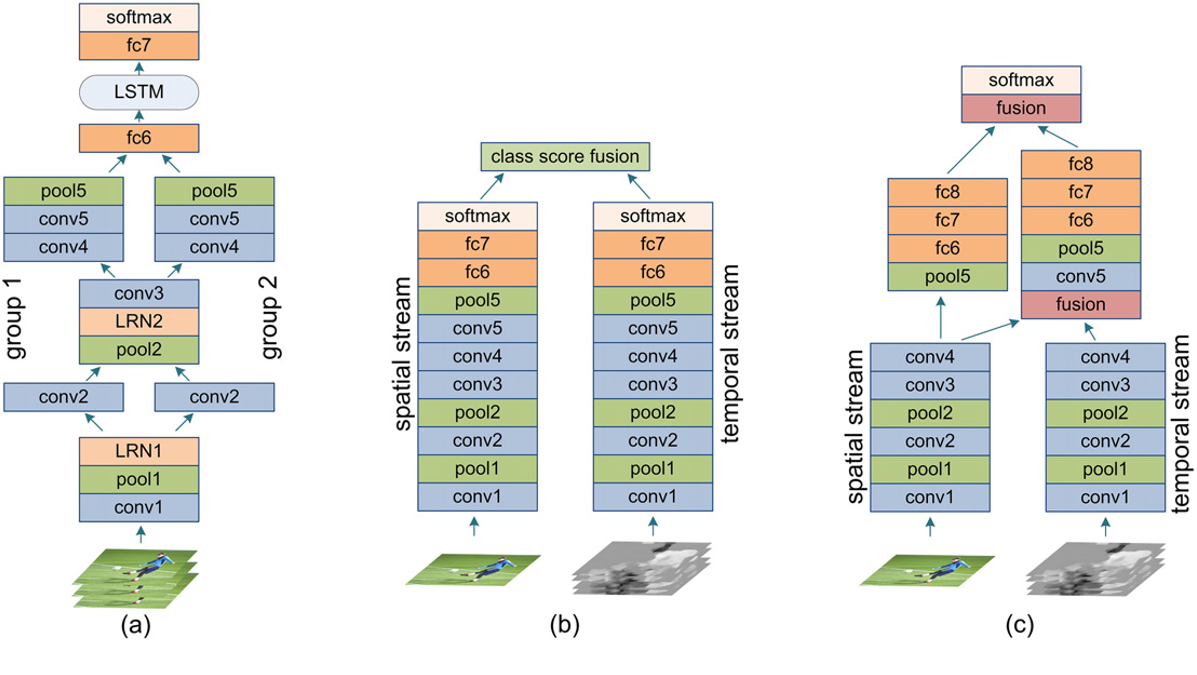
- slow fusion可以增强神经网络对时序的认知;在slow fusion中,相同的几个层接收几个连续的视频片段,输出再输入到全连接层,由此得以描述视频;
- 其他的fusion方法:early fusion: 逐帧特征加入到最后一层;Karpathy提出的方法:使用两个网络,能够增加精确度,同时减少需要学习的参数,因为每支网络能接受较小的输入,
 在这个示例中,fovea stream能注意到视频中央的区域,利用了摄像机的偏差,即兴趣点大多出现在视频中央;
在这个示例中,fovea stream能注意到视频中央的区域,利用了摄像机的偏差,即兴趣点大多出现在视频中央; - Tran等人的工作: 只使用
的卷积核效果更好; - 增加输入的时间的长度,同时结合使用具有不同对时间的意识的网络,能够提高神经网络的表现;
- 结合使用2D和1D的卷积核能减少3D卷积核对参数数量的需求;
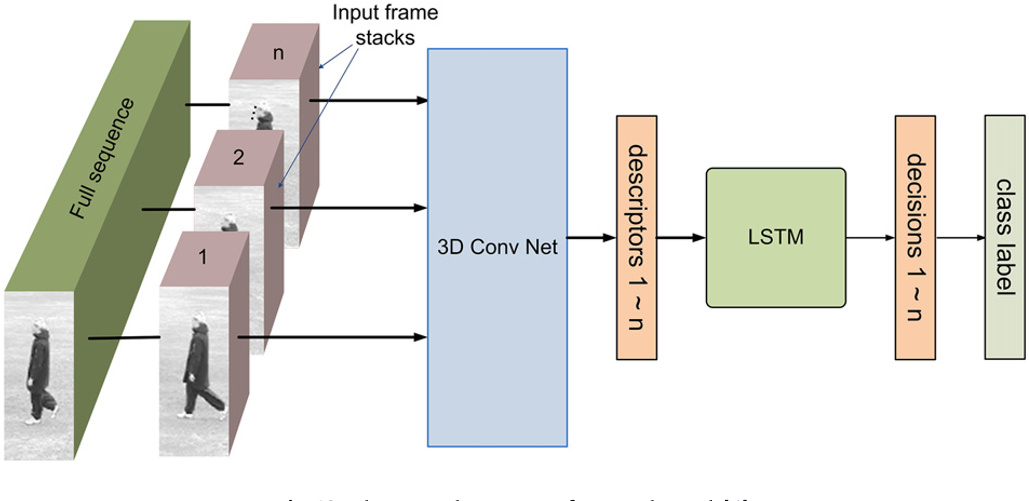
- Baccouche与Donahue等人:一系列卷积神经网络+LSTM,充分利用了时间信息;为了检测动作,Baccouche等人建议将三维卷积网络提取的特征输入到LSTM中;
- Donahue等人:Long-term Recurrent Convolutional Network (LRCN)
 在这个示例中,fovea stream能注意到视频中央的区域,利用了摄像机的偏差,即兴趣点大多出现在视频中央;
在这个示例中,fovea stream能注意到视频中央的区域,利用了摄像机的偏差,即兴趣点大多出现在视频中央;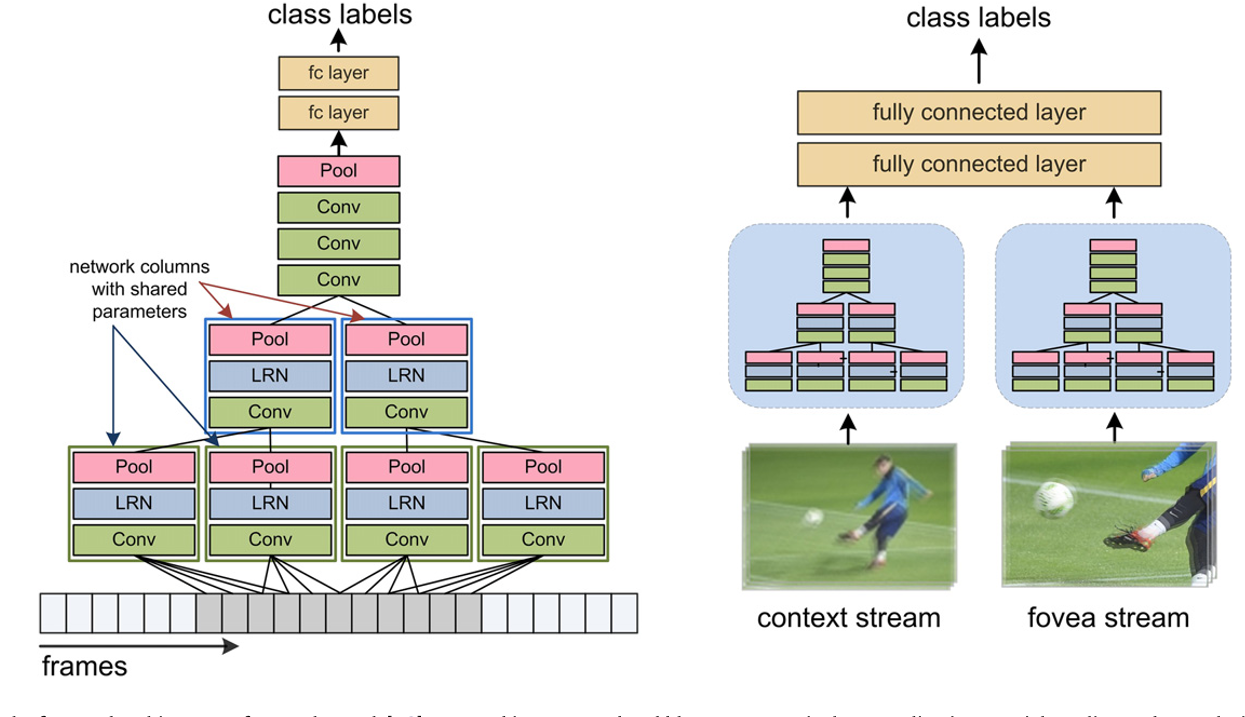
Multiple stream networks
1. Simonyan与Zisserman的双流网络
结构如下:
这是两个并行的网络。
- 使用预训练的模型
- 输入时堆叠时序信息
- 有多个classification layer,每个在不同的训练集上训练,这是一种多任务学习
双流网络使用softmax将两个流连接起来,在中间层融合可以表现得更好,同时减少需要学习的参数;在卷积层后融合可以减少对两个流的全连接层的需求;这个网络还可以进一步拓展:使用Fisher Vector,增加第三条支流来增加音频信号。双流网络中,播放的帧是唯一与动作相关的输入,这使双流网络无法捕获持续时间长的微小动作,将网络与手动提示结合起来可以改善这个问题。
Deep generative models
几种模型如下:
- Dynencoder
- LSTM autoencoder model
- Adversarial models
- Temporal coherency networks
Dynencoder
最基础的版本包含三层,第一层将输入
LSTM Dyencoder
构造如下: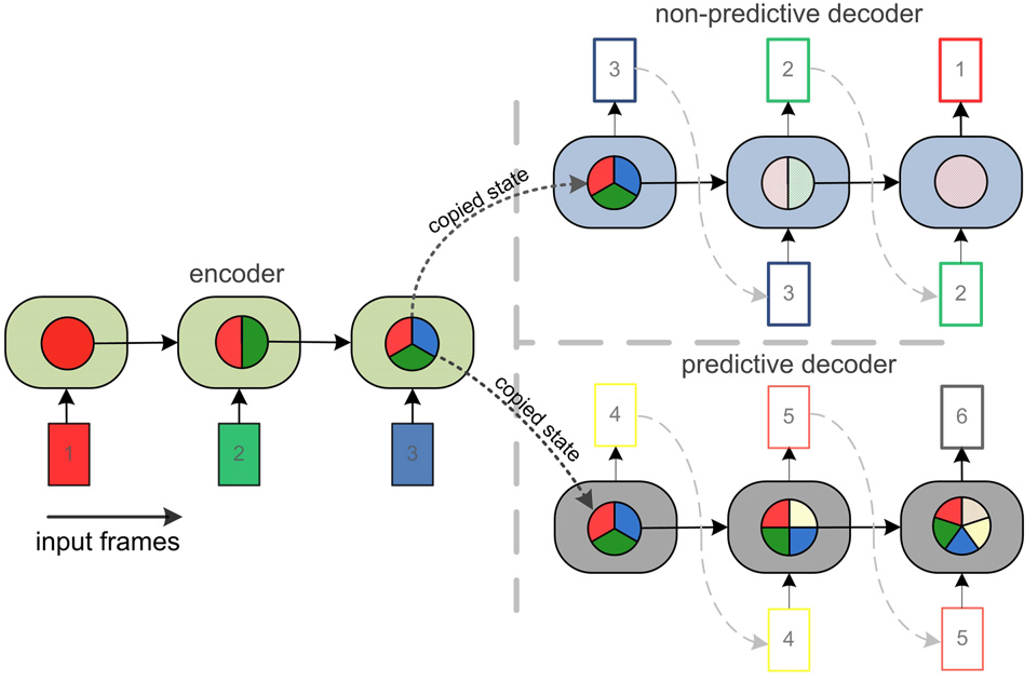
Adversarial models
对抗网络
Temporal coherency networks
一种弱监督学习的方法,用元组训练,判断动作是否连续。以Siamese Network为例: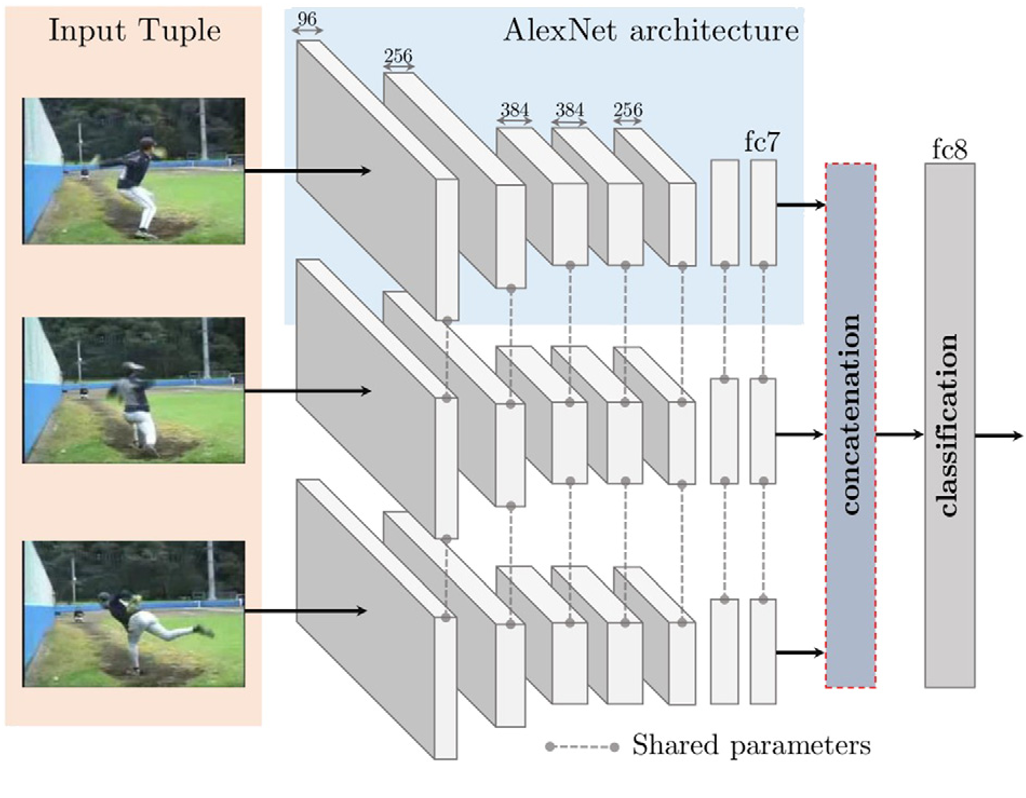 注意对时间上的连续性不一定意味着可靠性,比如插播广告时也是连续的,但显然广告与正片没有相关性。
注意对时间上的连续性不一定意味着可靠性,比如插播广告时也是连续的,但显然广告与正片没有相关性。
Wang等人的工作:将动作划分为两个阶段来识别,将动作划分为前提(precondiction)和效果(effect),使用Siamese Network,构造如下: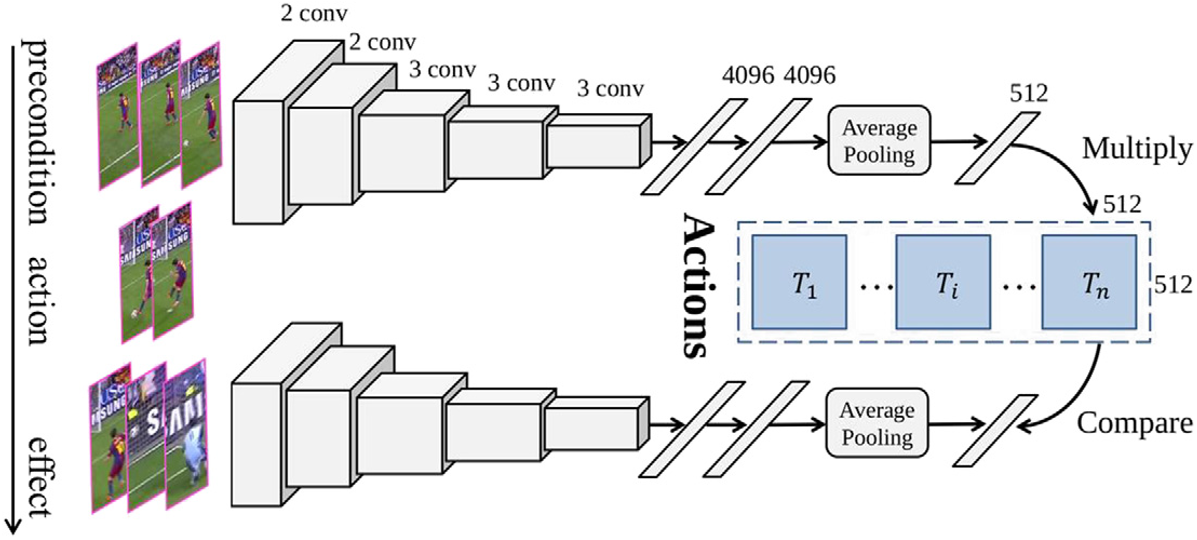
Rank pooling可以用来捕捉动作序列中的时序变化。
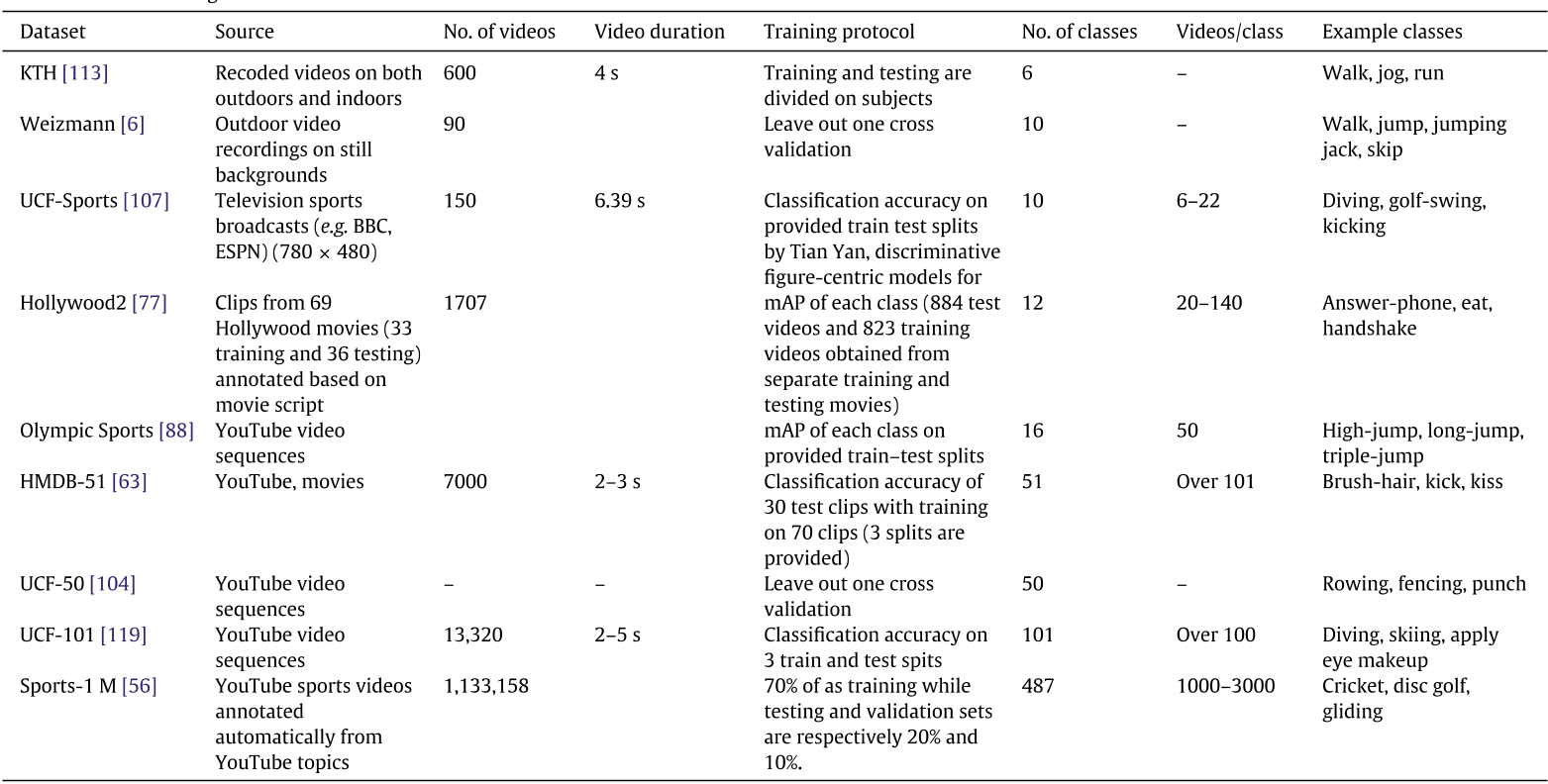
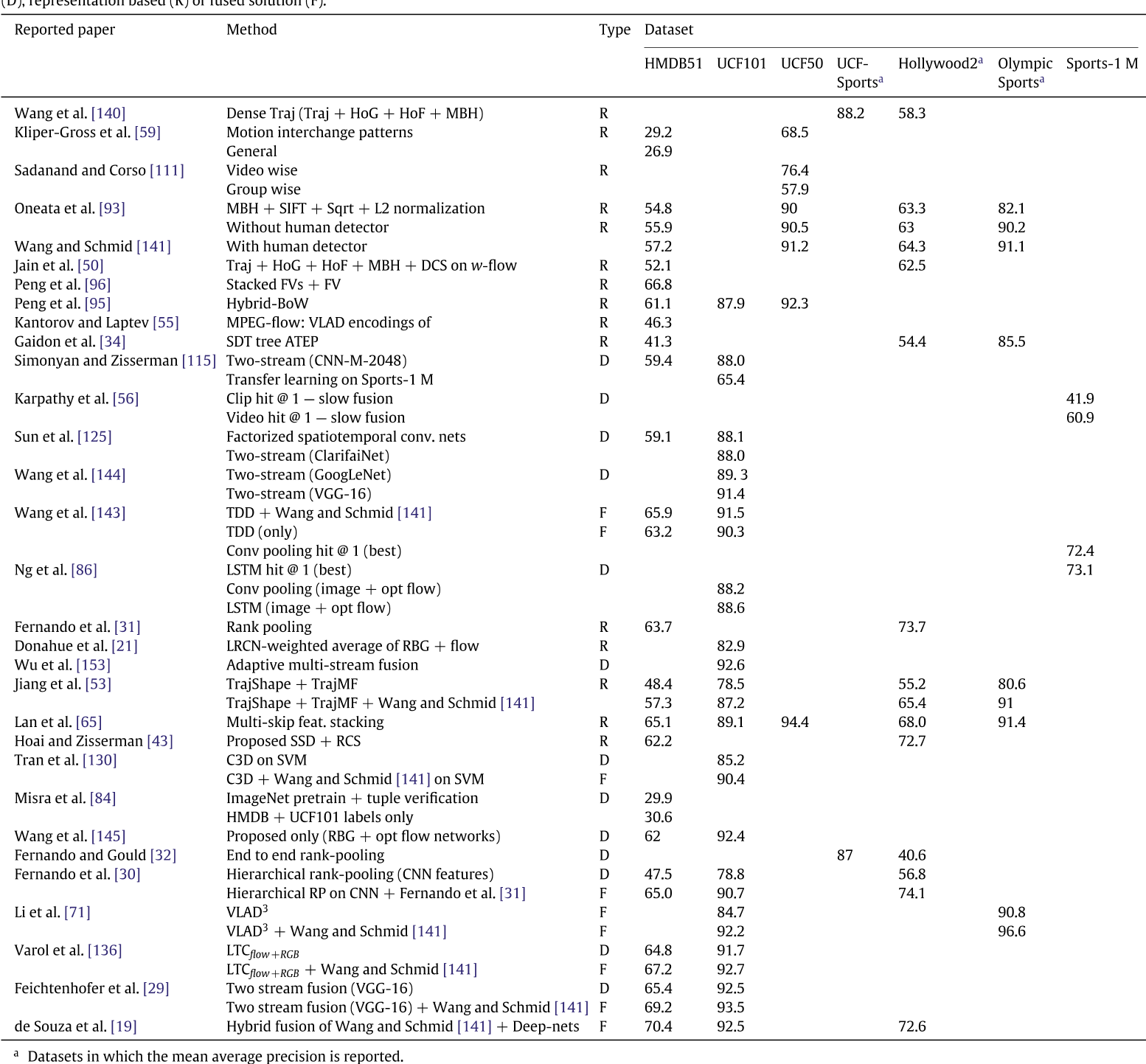
本篇综述剩下的内容是对与不同网络表现的数值分析,上图:
- 标题: 动作识别综述笔记
- 作者: MelodicTechno
- 创建于 : 2024-08-26 21:26:51
- 更新于 : 2026-02-17 18:51:17
- 链接: https://melodictechno.github.io./2024/08/26/har1/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论