
Modality for HAR

论文:Human Action Recognition From Various Data Modalities: A Review
封面:薛喵M
这篇综述侧重讲解了动作检测中不同的建模方式。
本来只是记笔记,然后变成翻译,最后变成机器翻译,从笔记变成大段落摘抄(复制粘贴)了。说实话我也不知道综述要怎么记笔记,综述不就是笔记吗🥲
不同的建模方法
提到了10种建模方式,优缺点已列出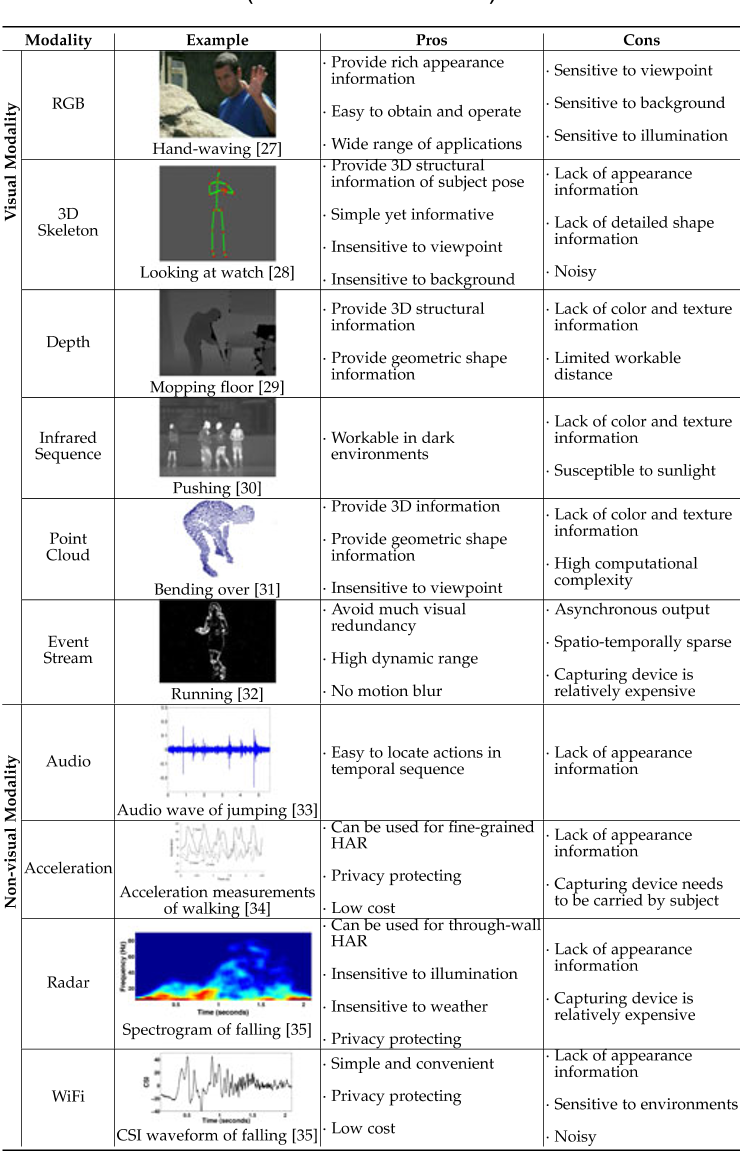
RGB
使用RGB摄像机获取,大部分相关工作使用视频,少部分工作使用静止的图片。
在深度学习早期,很多方法是手工的。基于时间,空间,体积的的方法,基于空间上的兴趣点的方法,基于运动轨迹的方法等,都适用与RGB建模。现在的主流是设计网络。
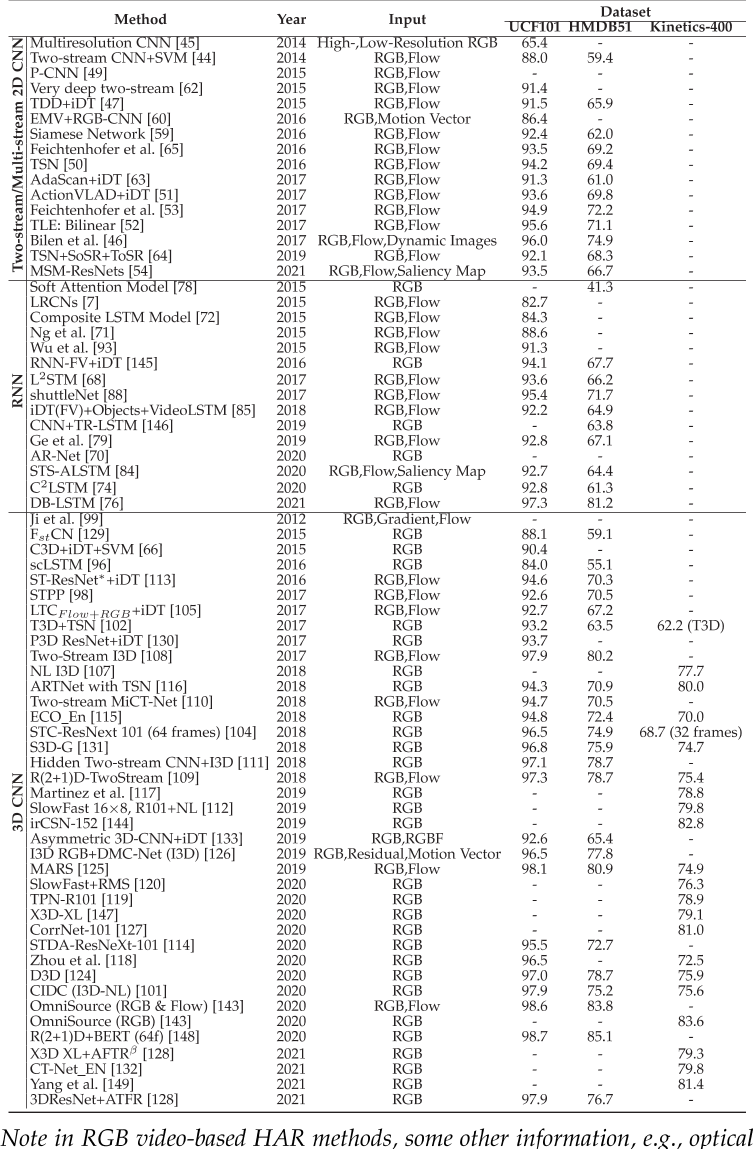
现在的网络可以分为三种:
- 双流二维卷积神经网络
- 循环神经网络
- 三维卷积网络
三种网络的整理如下:
双流网络
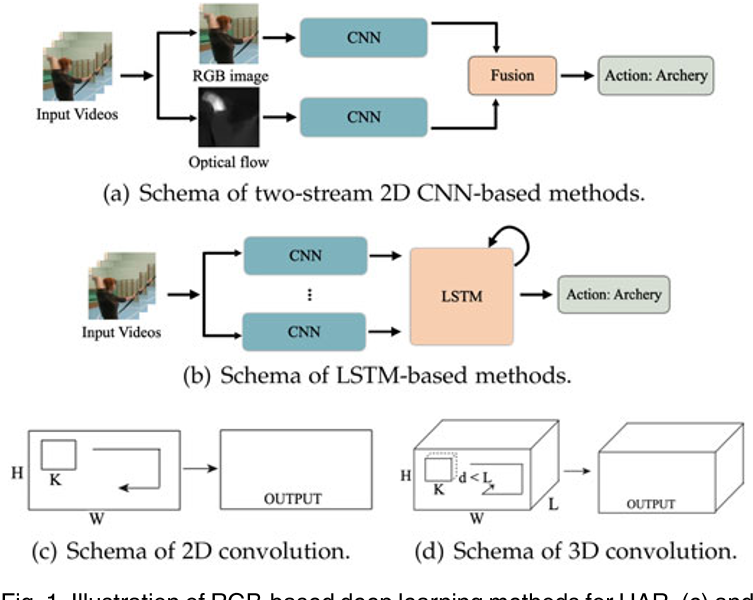
双流网络有两个二维卷积网络分支,从RGB视频例提前两种不同特征后输入两个分支,最终结果通过fusion两条分支的结果得到。
在经典的双流网络中,Simonyan与Zisserman使用了空间的网络和时间的网络,分别输入两个流;另一个经典的设计由Karpathy完成,两个流分别接收视频中央部分
裁切下来的视频,一个分辨率低,一个分辨率高,这样能提高计算的速度。
Wang等人将不同大小的帧和光流输入两个流,由此提取卷积特征图,然后以提取的轨迹为中心进行采样,用Fisher Vector聚合,再输入到SVM里。
其他工作:
Wang: 将视频分成3段,每段分别使用双流网络处理,检测的评分用平均池化融合,得到对视频的预测;
Diba: 用逐元素乘法将没一节视频的特征
Girdhar: 基于双流网络采样表现和动作的帧,提取特征,然后使用描述动作的词语的词典来将特征聚合成视频级的表征,用来检测动作。
Feichtenhofer: 将特征层面的动作信息与外观残差特征相乘,用来实现门控调制。
Zong: 通过增加动作特征流将双流网络拓展成三流网络,实现更好地捕捉动作特征信息
Bilen: 使用rank pooling,用RGB流和光流构建动态图,从而归纳全局的表观和动作。动态图,RGB图和光流图共同输入多流网络中,用来实现动作检测。
光流法的问题
计算光流的开销很大,为解决这个问题,Zhang等人提出一种teacher-student framework,将用光流信息训练的导师网络迁移到用动作向量训练的学生网络,动作向 量可以通过压缩的视频获得,不需要额外的计算。
Piergiovanni等人提出一种可以训练的flow layer,它不需要计算光流就可以捕捉动作特征。
在其他方面拓展双流网络的工作
Wang等人提出一种更深的双流CNN;Kar等人递归地预测每一帧对于动作检测的重要性;Zhang等人为了在低分辨率的视频上实现动作检测,提出了两种方法生成高分辨率 的视频;一些工作证明在最后一个卷积层融合空间和时间网络能够在减少网络参数的同时提高准确率。
RNN
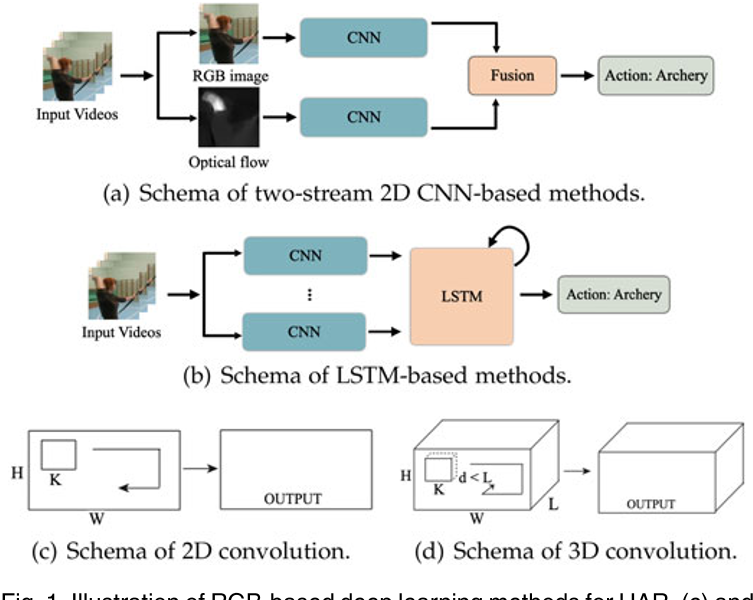 基于RNN的方法一般使用二维卷积网络来提取特征,再用一个lstm来检测动作,Donahue等人提出了LRCN,这种网络用2d cnn提取帧级的rgb信息,然后用lstm实现对动作的标记。吴恩达等人从预训练的二维卷积神经网络提取帧级别的rgb和图片流的特征,然后把这些特征输入到lstm堆栈,实现动作检测;编码lstm也可以用来将输入的视频映射到固定长度的representation里,然后用解码lstm解码,完成无监督的视频重建和预测。Wu等人使用两个lstm,分别操作与稀疏和精细的的cnn特征,共同实现高效的动作检测。Majd和Safabakhsh提出一种
基于RNN的方法一般使用二维卷积网络来提取特征,再用一个lstm来检测动作,Donahue等人提出了LRCN,这种网络用2d cnn提取帧级的rgb信息,然后用lstm实现对动作的标记。吴恩达等人从预训练的二维卷积神经网络提取帧级别的rgb和图片流的特征,然后把这些特征输入到lstm堆栈,实现动作检测;编码lstm也可以用来将输入的视频映射到固定长度的representation里,然后用解码lstm解码,完成无监督的视频重建和预测。Wu等人使用两个lstm,分别操作与稀疏和精细的的cnn特征,共同实现高效的动作检测。Majd和Safabakhsh提出一种
注意力
Sharma:多层lstm递归产生attention map,关注重要的空间信息,实现更好的检测效果;
Sudhakaran:带有内建空间注意力的递归单元,在空间上定位视频的偏差信息
Li:提出Video-LSTM,将卷积和基于动作的注意力合并入soft-attention LSTM,从而更好地捕捉动作和空间信息。
GRUs
能更好解决纯粹的RNN的梯度消失问题,较LSTM有更少的门,更少的模型参数,但是在动作检测方面表现和LSTM差不多
混合结构
组合2D CNN和RNN。例如Wu利用双流2D CNN提取空间和短期动作特征,然后分别输入到LSTM里完成对时序信息的建模。
基于三维卷积的方法
Tran: 3D CNN模型,即C3D,在端到端网络中从视频里学习时空特征,主要用于片段层面的学习
Diba: 使用3D卷积核和pooling kernals来拓展DenseNet,并设计了一个时序三维卷积网络(T3D),在这个网络中,时间过渡层可以对多种时序卷积核的深度进行 建模,T3D可以稠密且有效地捕捉多种长度视频的表观和时序信息。之后他们又将一些网络块嵌入一些结构,比如ResNext和ResNet,从而实现在时空特征方面对3维卷积 核的内部通道之间的联系的建模。
Varol: 提出一种长期时序卷积(LTC)网络,以减少空间分辨率为代价延长三维卷积网络表达时间信息的极限,完成对长时间的时序结构的建模。
Hussein: 提出多种大小,只关注时序的卷积,又称为时间感知(Timeception),用来应对复杂而持续时间长的动作的多样性和时间长短的不同。
Wang: 提出一种非本地的操作,在特征图中对任意两个位置的关系之间进行建模,从而捕捉长范围的依赖。
Li: 提出通道独立的方向卷积(CIDC),可以被加在I3D之后以更好地捕捉完整视频的长期时序动态。
3D CNN外加双流或多流
Carreira与Zisserman: two-stream inflated 3d cnn(I3D),用具有额外时序维的二维卷积核膨胀卷积和池化核
Wang: two-stream cnn 与lstm融合,捕捉长距离时序依赖
Feichtenhofer: 包含slow pathway和fast pathway的two-stream 3d cnn,对慢速和高速的rgb帧分别捕获语义和动作
Li: 双流时空可变形3d cnn,外加注意力,可以捕获长范围的时序和长距离的空间依赖
对3D CNNs问题的解决
Zhou: 从概率的角度分析3D CNN的时空融合
Yang: 提出通用的网络,Temporal Pyramid Network(TPN),对动作中速度的变化进行建模
Kim: 提出Random Mean Scaling (RMS),一种正则化方法,已处理过拟合的问题
Varol: 用合成的动作训练3D CNN,让训练集的视点更多元
Piergiovanni与Ryoo: 几何卷积层,学习3D几何变化和投影
蒸馏法可以改善3D CNN对动作的表示
Stroud: Distilled 3D Network (D3D),由学生网络和导师网络组成,学生网络用RGB视频训练,导师网络用光流序列训练,得到的信息蒸馏给学生网络
Crasto: 用光流训练的导师网络的知识迁移到用RGB视频训练的学生网络,减少特征图和双流的均方误差
下面是一些减少计算量的方法
Shou: 对抗网络,通过减少压缩后的视频中噪音和粗粒的动作来估计动作信息
Wang: 高效的correlation operator,更好地学习3D特征图的动作信息
Fayyaz: 动态改变时序特征的分变率,提出Similarity Guided Sampling (SGS)模块,让3D CNNs能够选择信息量最大和最有特点的时序特征,动态地选择计算资源,
因式分解三维卷积
Sun: Factorized spatio-temporal CNN (
Qiu: 在空间上将三维卷积分解成二维卷积,之后是时间域上的一维卷积,能够经济有效地模拟三维卷积
Xie: 利用了三维和二维卷积核的组合,探索了几种I3D变体的表现,引入了一种时间可分离卷积和空间特征门来增强动作检测
Yang: 高效的单向三维卷积,实现对传统卷积的近似
Lin: Temporal Shift Module (TSM),沿着时间部分交换通道
Sudhakaran: 轻量的Gate-Shift Module (GSM),使用可学习的空间门块,完成对三维卷积的时空分解
Wang: 双层Gate-Shift Module (GSM),捕捉精细的局部和大范围的全局动作
Wang: Action模块,利用多径激励分别在时空层面,通道层面和动作模式方面建模
其他方法: Convolutional Gated Restricted Boltzmann Machines, Graph-based Modeling, Transformers, 4D CNNs
Skeleton Modality
- 编码关节
- 可以用动捕收集
- 在大多数场景不方便
- 一般用深度图或RGB获取骨架建模
- 简单有效多样健壮
一些基于骨架建模的网络: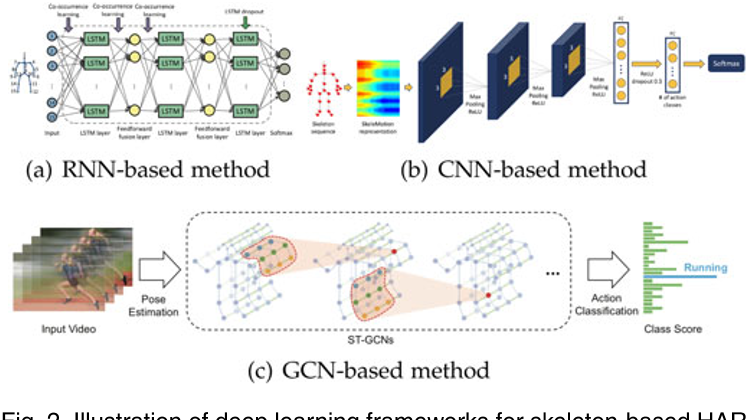
它们的表现: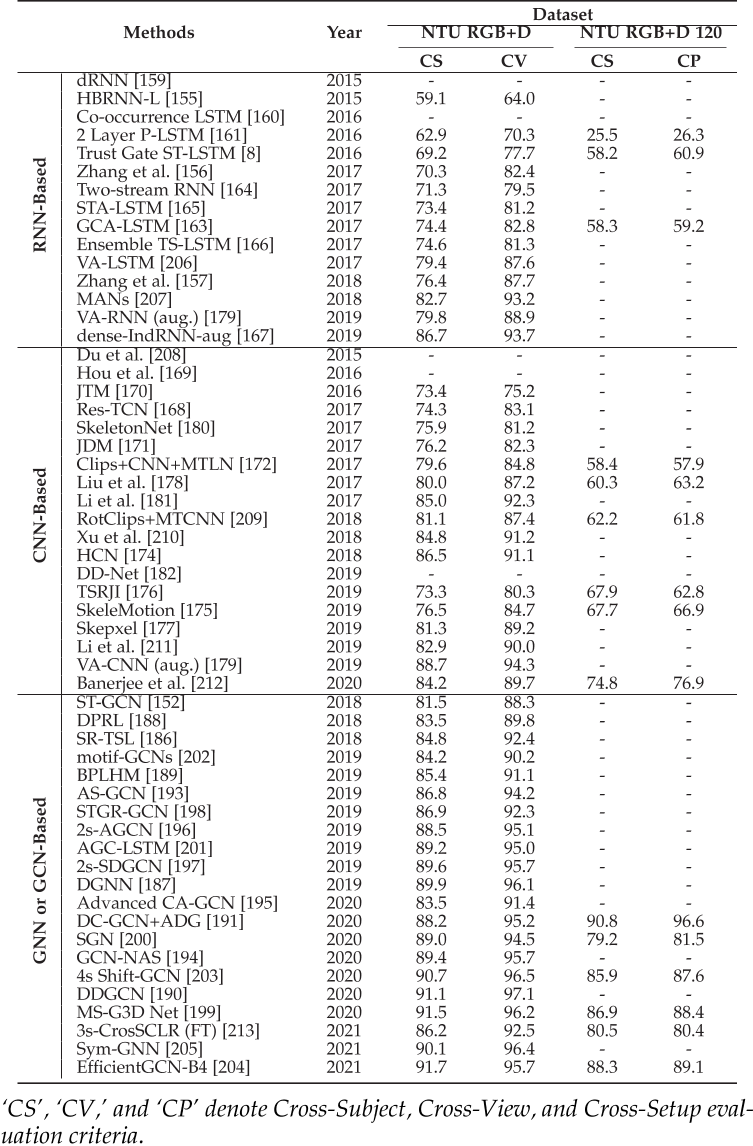
基于RNN的方法
Du: 端到端层次RNN,将骨架分为5个部分,分别输入多个双向RNN,输出一层层混合,在较高位面生成对动作的表示
Differential RNN (dRNN),通过量化帧之间显著运动引起的信息增益的变化来学习显著的时空信息
Derivative of States (DoS),在lstm单元里作为控制信息在内部单元流入流出的信号
Zhu: lstm新的机制,实现co-occurrence mining,共现(co-occurrence)本质上表征了动作
Sharoudy: Part-aware LSTM (P-LSTM),引入在lstm里模拟身体各部分的关系的机制
Liu: 在时间和空间上拓展RNN,利用基于树结构的骨架遍历方法,进一步利用空间信息,用trust gate处理噪声和闭塞;基于注意力的lstm,Global Context-Aware Attention LSTM (GCA-LSTM),使用全局信息选择性地关注信息关节。模型包含两层lstm,第一层编码骨架序列,输出全局上下文记忆,第二层输出注意力,精细化全局上下文,最后softmax输出动作识别信息
two-stream RNN建模时间动态和空间立体基阵
Deep LSTM + 时空注意力,空间注意力子网络和时间注意力子网络共同在主要的lstm下工作,对骨架序列的多种动态进行建模
Lee: Temporal Sliding LSTM (TS-LSTM) framework,由多个部分组成,包含短,中,长期TS-LSTM
IndRNN: 解决梯度消失和梯度爆炸,比原本的lstm快
基于CNN的方法
Hou: 骨架光谱+关节轨迹图,将时空信息和骨架序列编码成色彩纹理图,使用CNN做动作识别
Joint Distance Map (JDM), 上述工作的延申,用骨架关节的距离对生成视角不变的色彩纹理图
Ke: 将每个骨架序列转换成三个视频片段,输入预训练的CNN,产生微缩的表示,然后用多任务网络har
Kim: Temporal CNN (TCN),清晰提供可读的时空表示
一种用层次的方法学习共现特征的端到端网络,在点的层面单独地学习关节的每个特征,利用这些特征作为卷积层的一个通道,学习层次的共现特征,使用双流网络融合动作特征
Caetano: SkeleMotion,Tree Structure Reference Joints Image (TSRJI),用来表示骨架序列。
Skepxels,构建骨骼图的基本块,用来编码人体骨骼关节的位置和速度的时空信息,也可以用来捕捉在每一帧间关节极微小的动作之间的联系。Fourier Temporal Pyramids 可以利用这些联系
解决问题
Double-feature Double-motion Network (DD-Net): 加快计算
Tang: 提出了一种无监督域适应设置下的自监督学习框架,该框架对时间段或身体部位进行分割和排列,以减少域偏移,提高模型的泛化能力。
GNN或基于GCN的方法
Yan: 通过引入时空GCNs (ST-GCNs),利用GCNs进行基于骨架的HAR,可以自动从骨架数据中学习空间和时间模式 fig2c
Li: 进一步提出了一种动作结构 GCN (ASGCN),将动作链接和结构链接组合成一个广义骨架图。动作链接用于捕获特定于动作的潜在依赖关系,结构链接用于表示高阶依赖关系。
Peng: 通过神经架构搜索方案确定他们的 GCN 架构。具体来说,他们丰富了搜索空间,以隐式捕获基于多个动态图子结构和与切比雪夫多项式近似的高阶连接的联合相关性。
Shi: Shi等人提出了一种双流自适应GCN (2s-AGCN),模型中图的拓扑结构可以通过反向传播算法统一或单独学习,而不是手动设置它。2s-AGCN 将骨架的二阶信息(人体骨骼的长度和方向)与一阶信息(关节坐标)显式组合。
Wu: 引入了一个跨域空间残差层来捕获时空信息,以及一个密集连接块来学习基于ST-GCN的全局信息。将骨架序列的帧骨架和节点轨迹馈送到空间图路由器和时间图路由器以生成新的骨架关节连接图,然后使用ST-GCN进行分类。
Liu: 集成了解纠缠的多尺度聚合方案和一个名为G3D的时空图卷积算子来实现强大的特征提取器。”Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition”中引入了关节的高级语义,注意力机制用于提取判别信息和全局依赖关系。
Cheng: 此外,为了降低 GCN 的计算成本,Cheng 等人设计了一个 Shift-GCN,采用移位图运算和轻量级的逐点卷积,而不是使用繁重的正则图卷积。
Song: Song等人提出了一种多流GCN模型,该模型在早期阶段融合了关节位置、运动速度和骨骼特征等输入分支,并利用可分离卷积层和复合缩放策略,在增加模型容量的同时,极大地减少了冗余可训练参数。
Li: 提出了共生GCNs,可以同时处理动作识别和运动预测任务。提出的Sym-GNN由一个多分支多尺度GCN和一个动作识别和一个运动预测头组成,共同进行动作识别和运动预测任务。这允许两个任务相互增强。
深度模态(Depth Modality)
一些基于深度的 HAR 方法在几个基准数据集上的结果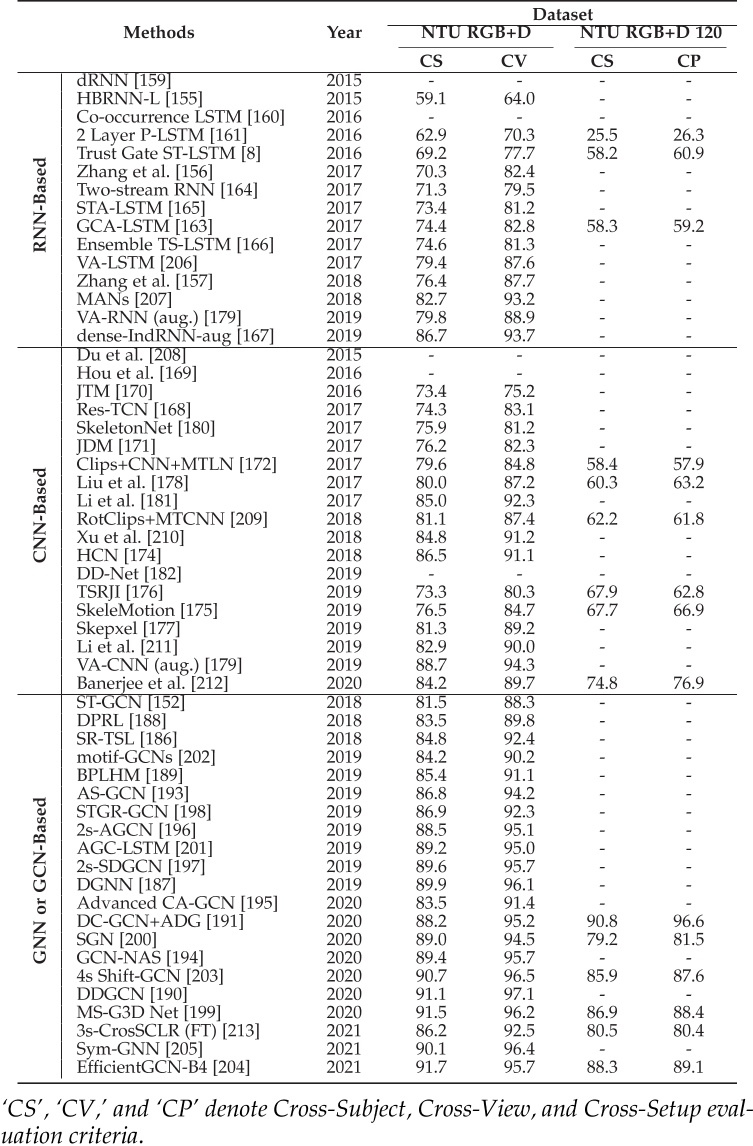
Wang: 建议用身体、身体部位和关节级别的三对结构化动态图像表示深度序列,然后将其馈送到CNN,然后加上用于细粒度HAR的分数融合模块。
Rahmani: 利用 CNN 模型来学习视图不变的人体姿势模型,用傅立叶时间金字塔来模拟时间动作变化。为了获得更多的多视图训练数据,通过将合成的 3D 人体模型拟合到真实的动作捕捉数据中来生成合成数据,并从各个视点渲染人体数据。
通过深度视频的多视图投影提取多视图动态图像进行动作识别。
为了有效地捕捉深度视频中的时空信息,Sanchez等人提出了一种用于HAR的三维全CNN架构。在他们后续工作中,引入了LSTM单元的变体来解决视频处理过程中内存限制的问题,该问题可用于从长视频和复杂视频中执行HAR。
除了使用主动传感器或立体相机获得的深度图进行HAR外,还有另一种方法设计用于RGB视频中的基于深度的HAR。具体来说,Zhu和Newsam使用现有的深度估计技术从RGB视频中估计深度图,然后通过深度学习架构进行动作分类。
红外模态(Infrared Modality)
首先通过人体区域的重心对极低分辨率的热图像进行裁剪。然后将裁剪后的序列和帧差异传递给 CNN,然后使用 LSTM 层对 HAR 的时空信息进行建模。
为了同时从热视频中学习空间和时间特征,Shah等人利用 3D CNN,实现实时HAR
Meglouli等人没有使用原始热图像。从热序列计算的光流信息传递到3D CNN中用于HAR。
下面是一些受双流网络启发的工作
Raman提出了一种四流架构,其中每个流由一个CNN和一个 LSTM 组成。将局部/全局叠加密集流差图像和局部/全局叠加显著性差图像输入到这四个流中,以捕获视频中的局部和全局时空信息。
Mehta等人提出了一个对抗性框架,该框架由双流3D卷积自动编码器作为生成器和两个3D CNN作为联合鉴别器组成。生成器网络以热数据和光流为输入,联合鉴别器试图将真实的热数据和光流与重构的目标数据区分开来
点云模态(Point Cloud Modality)
Wang等人将原始点云序列转换为常规体素集。然后将时间秩池应用于所有体素集,将3D动作信息编码为单个体素集。最后,体素表示被抽象并通过 PointNet++ 模型进行 3D HAR。然而,将点云转换为体素表示会导致量化误差和低效的处理性能
Liu等人提出了MeteorNet,它直接堆叠多帧点云,并通过聚合来自时空相邻点的信息来计算局部特征
与通过将一维时间维度附加到 3D 点来学习时空信息的MeteorNet不同,PSTNet解开空间和时间,以减少点的空间不规则性对时间建模的影响
Fan: 引入了点云4D卷积,加上一个Transformer来捕获整个点云视频中的全局外观和运动信息。
在Self-supervised 4D Spatio-temporal Feature Learning via Order Prediction of Sequential Point Cloud Clips的工作中,引入了一个自监督学习框架,通过预测序列中4D剪辑的时间顺序,从点云序列中学习4D时空信息。使用4D CNN模型和LSTM来预测时间顺序。最后,在现有HAR数据集上微调4D CNN+LSTM网络以评估其性能。
Wang等人在”Anchor-Based Spatial-Temporal Attention Convolutional Networks for Dynamic 3D Point Cloud Sequences”中提出了一种基于锚定的时空注意力卷积模型来捕捉三维点云序列的动力学。然而,这些方法不能充分捕捉点云序列中的长期关系,为了解决这个问题,Min 等人在An Efficient PointLSTM for Point Clouds Based Gesture Recognition中引入了一个名为 PointLSTM 的 LSTM 单元的修改版本来更新相邻点对的状态信息以执行HAR。
Spatial-Temporal Transformer for 3D Point Cloud Sequences中提出了一种用于处理点云序列的点时空转换器(PST2)。引入了一种基于自注意力的模块,称为时空自注意力 (STSA),用于捕获时空上下文信息,可用于 3D 点云中动作识别。
事件流模态(Event Stream Modality)
Innocenti等人在Temporal Binary Representation for Event-Based Action Recognition中首先通过检查
Huang等人在Event-based Action Recognition Using Timestamp Image Encoding Network利用时间戳图像编码将事件数据序列转换为基于帧的表示,然后将其馈送到CNN进行HAR。更准确地说,生成的时间戳图像中每个像素的值编码了发生在时间窗口内的事件量。
Ghosh等人以无监督的方式学习一组3D时空卷积滤波器,生成原始事件数据的结构化矩阵形式,然后将其馈送到3D CNN进行HAR。George等人利用Spiking神经网络(SNNs)进行基于事件流的HAR。Space-Time Event Clouds for Gesture Recognition: From RGB Cameras to Event Cameras中的工作将事件流视为三维点云,然后将其馈送到PointNet进行手势识别。Bi等人将事件表示为图,并使用 GCN 网络直接从原始事件数据中学习端到端特征学习。
音频模态(Audio Modality)
近年来,仅用音频信号中实现HAR的深度学习方法只有几种
Liang 和 Thomaz在Audio-Based Activities of Daily Living (ADL) Recognition with Large-Scale Acoustic Embeddings from Online Videos中使用预训练的 VGGish 模型作为特征提取器,然后是深度分类网络来执行HAR。
加速度模态(Acceleration Modality)
Wang等人在Human Action Recognition on Cellphone Using Compositional Bidir-LSTM-CNN Networks中提出了一个由CNN和Bi-LSTM网络组成的框架,从原始加速度数据中提取空间和时间特征。与上述工作不同,Lu等人在Robust Single Accelerometer-Based Activity Recognition Using Modified Recurrence Plot中利用改进的递归图(RP)将原始三轴加速度数据转换为彩色图像,然后将其馈送到ResNet进行HAR。此外,一些基于加速的方法(如Accelerometer-Based Human Fall Detection Using Convolutional Neural Networks)专注于跌倒检测任务。
雷达模态(Radar Modality)
雷达是一种主动传感技术,传输电磁波并从目标接收返回的波。连续波雷达,如多普勒和频率调制连续波(FMCW)雷达,最常被选为HAR。具体来说,多普勒雷达检测身体部位的径向速度,频率根据距离变化,称为多普勒频移。雷达微运动产生的微多普勒特征包含目标的运动和结构信息,因此可用于HAR。至于FMCW雷达,它们也可以测量目标的距离。使用雷达获得的HAR谱图有一些优点,其中包括对光照和天气条件的变化、隐私保护和穿墙HAR的能力的鲁棒性。
Human Activity Classification With Radar: Optimization and Noise Robustness With Iterative Convolutional Neural Networks Followed With Random Forests中的工作直接将原始雷达距离数据作为输入。原始数据通过一个自相关函数,然后是一个 CNN 来提取与动作相关的特征。最后,使用随机森林分类器来预测动作类别。
双流
Hernanguliomez等人在中设计了一种双流CNN,将表示目标结构特征的微多普勒和距离谱图作为输入。在中,雷达的微多普勒谱图和回波被馈送到双流CNN模型进行HAR。
RNN
通过将微多普勒谱图解释为时间序列而不是图像,最近提出了几种基于 RNN 的架构。例如,Yang和Wang分别使用LSTM模型和堆叠的RNN模型来预测动作类。
WIFI
信道状态信息(CSI)是从原始 WiFi 信号计算的细粒度信息,由执行动作的人反射的 WiFi 信号通常在 WiFi 接收器上产生 CSI 的独特变化
Wang等人提出了一种深度稀疏自动编码器来从CSI流中学习鉴别特征。在 的工作中,提出了基于 WiFi 的样本级 HAR 模型,称为 Temporal Unet,由几个时间卷积、反卷积和最大池化层组成。该方法将每个系列中的每个WiFi失真样本分类为细粒度HAR的一个动作。LSTM网络也被用于HAR使用CSI信号Huang等人通过噪声和冗余去除模块传递原始CSI测量值,然后使用剪辑重建模块将处理后的CSI信号分割成多个片段。然后将这些剪辑馈送到多流 CNN+LSTM 模型以执行 HAR。在的工作中,首先从预先训练的CNN的全连接层中提取CSI信号的空间特征。然后将这些特征馈送到 Bi-LSTM 以捕获 HAR 的时间信息。Chen等人通过基于注意力的BiLSTM直接传递原始CSI信号来预测动作类别。与上述工作不同,Gao等人将CSI信号转换为无线电图像,然后将其馈送到深度稀疏自动编码器来学习HAR的鉴别特征。
多模态
在现实生活中,人类经常以多模态认知的方式感知环境。同样,多模态机器学习是一种建模方法,旨在处理和关联来自多种模式的感觉信息。通过聚合各种数据模式的优点和功能,多模态机器学习通常可以提供更健壮和准确的HAR。多模态学习方法主要有两种类型,即融合和共同学习。融合是指整合来自两个或多个模态的信息进行训练和推理,而共同学习是指不同数据模态之间的知识转移。
融合
HAR中有两种广泛使用的多模态融合方案,即分数融合和特征融合。通常,分数融合集成了基于不同模态的单独做出的决策(例如,通过加权平均或通过学习分数融合模型)来产生最终的分类结果。另一方面,特征融合一般将不同模态的特征结合起来,产生对HAR通常非常有鉴别性和强大的聚合特征。
视觉模态的融合
Fusion of RGB and Depth Modalities
在中,引入了一个四流深度CNN,从三个不同的视点)和RGB数据(即运动历史图像)的不同深度数据表示(即三个深度运动图)中提取特征。将这四个流的输出分数进行融合以执行动作分类。
通过将深度和 RGB 模态视为单个实体,Wang 等人从空间对齐和时间同步的 RGB 和深度帧中提取场景流特征。利用双向秩池从场景流特征序列中生成两个动态图像。然后将动态图像馈送到两个不同的 CNN,最后融合它们的分类分数来执行 HAR。
Wang等人[58]将RGB和深度数据表示为两对RGB和深度动态图像,然后通过协同训练的CNN (c-ConvNet)。c-ConvNet 由两个流组成,它们通过联合优化排名损失和 softmax 损失来利用特征进行动作分类。在[311]中,引入了一个由多流cnn和3D ConvLSTMs[349]组成的混合网络,从RGB和深度视频中提取特征。然后通过典型相关分析融合这些特征以执行动作分类。
Wang等人[309]提出了一个生成框架来探索RGB和深度模态之间的特征分布。融合是通过构建一个跨模态发现矩阵来执行的,然后将其馈送到模态相关发现网络进行最终预测。Dhiman等人[310]设计了一个由运动流和形状时间动态(STD)流组成的双流网络,分别对RGB和深度视频的特征进行编码。特别地,运动流从 RGB 数据中获取动态图像作为输入并输出分类分数。STD 网络由 [9] 中的人体姿势模型作为其主干,然后是几个 LSTM 和一个 softmax 层。通过聚合这两个流的分数得到最终的分类分数。
Fusion of RGB and Skeleton Modalities
RGB数据提供的外观信息和骨架序列提供的身体姿势和关节运动信息是互补的,对活动分析很有用。因此,一些工作研究了深度学习架构来融合HAR的RGB和骨架数据
Zhao等人[315]引入了一个双流深度网络,该网络由一个RNN和一个CNN组成,分别处理骨架和RGB数据。评估了特征融合和分数融合,前者取得了更好的性能。
融合CNN模型[316]或在骨架数据上训练的RNN模型[314]的分类分数和在RGB数据上训练的骨架条件时空注意网络,进行最终分类。
Zolfaghari[313]设计了一个三流3DCNN来处理姿态、运动和原始RGB图像。这三个流通过马尔可夫链模型进行融合以进行动作分类。Liu提出了一种时空LSTM网络,能够有效地融合LSTM单元内的RGB和骨架特征。
为了有效地捕捉动作执行的细微差异,Song等人[317]提出了一个学习框架,该框架包含两个骨架引导的深度CNN流,从RGB和光流中提取特征。
先到这里,感觉我方法不对
- 标题: Modality for HAR
- 作者: MelodicTechno
- 创建于 : 2024-08-26 21:34:23
- 更新于 : 2026-02-17 18:51:17
- 链接: https://melodictechno.github.io./2024/08/26/HAR2/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。